引入
项目中业务模块产生的日志在通过本地 socket 发送给日志模块后,日志模块记录的内容总是会丢失前6个字节。经过排查,业务模块和日志模块使用的虽然都是 log_msg_t 结构体,但结构体中的变量类型定义却略有差异,如下所示:
- 业务模块的结构体定义
1 | typedef struct{ |
- 日志模块的结构体定义
1 | typedef struct{ |
显然,由于结构体中 u8wf 变量类型的不同,导致出现了内容丢失。但 unsigned char 的大小为1个字节,unsigned int 的大小为4个字节,怎么会出现丢失6个字节的内容呢,这与结构体的内存对齐有关。
内存对齐
为什么需要对齐
在 C 语言中,结构体的内存对齐是编译器为了提高 CPU 访问内存效率而采取的一种内存布局优化策略,是一种拿空间换时间的做法。
CPU 访问内存时并非逐个字节读取,而是按固定大小的 “块”(如 4 字节、8 字节)读取。如果数据的起始地址是块大小的整数倍(即 “对齐”),CPU 可以一次完成读取;否则可能需要多次读取,影响效率。
内存对齐规则
第一个成员在与结构体变量偏移量为 0 的地址处。
其他成员变量的起始地址必须是
min(该成员自身大小, 编译器默认对齐数)的整数倍。结构体的总大小必须是所有成员中最大对齐值的整数倍,即
min(结构体中最宽成员类型的大小, 编译器默认对齐数)的整数倍。若不足,编译器会在最后一个成员之后添加填充字节以满足此要求。
练习
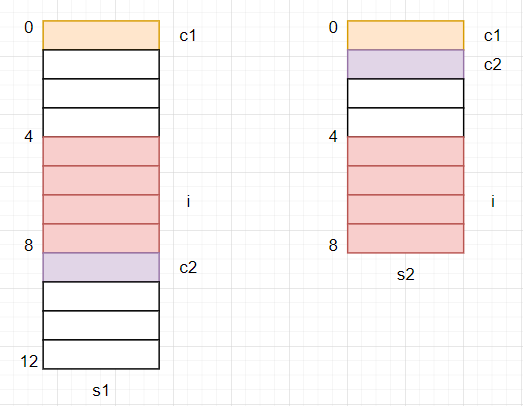
下面两个结构体的大小分别为多少?
1 | typedef struct{ |
S1 和 S2 的内存布局如下图所示:
相关函数
sizeof
- 获取结构体的大小
1 | printf("%ld\n", sizeof(S1)); |
offset 宏
- 计算结构体中某变量相对于首地址的偏移
- 头文件:
#include<stddef.h>
1 | printf("offsetof(S1, c1) = %ld\n", offsetof(S1, c1)); |
#pragma pack()
- 修改默认对齐数(谨慎操作)
1 | // 将默认对齐数修改为 8 |
TIPS
在设计结构体的时候要满足对齐规则,又要节省空间,如何做到呢?
- 在定义结构体时,将大小相同或相近的成员声明在一起,并且按照从大到小(或从小到大)的顺序声明,可以最大限度地减少填充字节,节省内存。
可变长数组
此外,可以看到 log_msg_t 的最后一个元素为 data[], 且如果使用 sizeof(log_msg_t),可能会发现结果并不符合预期,这一切都与可变长数组的特点相关。
介绍
变长数组是在 C 语言的 C99 标准中引入的新特性。结构体中的最后一个元素允许是大小未知的数组。
比如:
1 | struct S { |
特点
结构体中的可变长数组前面必须至少有一个其它类型的成员。
可变长数组必须是结构体的最后一个成员。
可变长数组不占用结构体的存储空间,使用 sizeof 计算结构体的大小不包含可变长数组成员。
结构体变量相邻的存储空间保存的是可变长数组的内容。
log_msg_t
因此,两个模块使用的log_msg_t结构体的内存布局如图所示:

可以看到两个结构体的 data 成员相对于起始地址的偏移量相差 6 个字节,这也就是为什么日志模块记录的内容总是会丢失前6个字节。
优势
使用指针
1 | struct S { |
那么在使用时就需要两次 malloc 和两次 free,
1 | struct S *ps = NULL; |
使用可变长数组
1 | struct S { |
使用时只需要一次 malloc 和 free,
1 | // 分配内存以容纳结构体S和10个整数的数组 |
总结
使用指针:
- 为了防止内存泄漏,如果分两次分配结构体和缓冲区的内存,当第二次 malloc 失败时,必须回滚释放第一次分配的结构体内存。
- 进行了两次 malloc,需要对应两次 free,如果我们的代码是在一个给别人用的函数中,我们在函数里做了两次内存分配,并把整个结构体返回给用户;虽然用户调用 free 可以释放结构体,但用户并不知道结构体的成员也需要 free,造成内存泄露。
- malloc 次数越多,产生的内存碎片就越多,内存的利用率就会降低。
使用变长数组:
- 连续内存有利于提高访问速度,同时减少内存碎片