2.1 BCC’s “Hello World”
示例 [hello.py]: 一个使用 BCC 的 Python 库实现的 eBPF “Hello World” 应用
1 | #!/usr/bin/python3 |
这段代码由两部分组成:
- the eBPF program: 运行在内核中
- user space code: 加载 eBPF 程序到内核中,并且读取其生成的跟踪信息
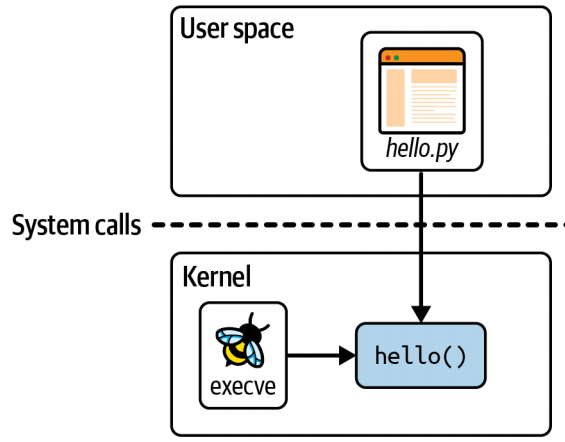
2.1.1 The eBPF program
1 | int hello(void *ctx) { |
这个 eBPF 程序所做的只是使用一个辅助函数(helper function) bpf_trace_printk() 来写一条消息。
内核中的 bpf_trace_printk() 辅助函数总是将输出发送到同一个预定义的伪文件位置:/sys/kernel/debug/tracing/trace_pipe。
2.1.2 user space code
- 创建 BPF 对象
1 | b = BPF(text=program) |
- 将
hello函数附加到系统调用execve。(只要机器上启动新的可执行文件,该程序就会被触发。)
1 | syscall = b.get_syscall_fnname("execve") |
- 读取内核输出的跟踪信息并将其输出到屏幕上
1 | b.trace_print() |
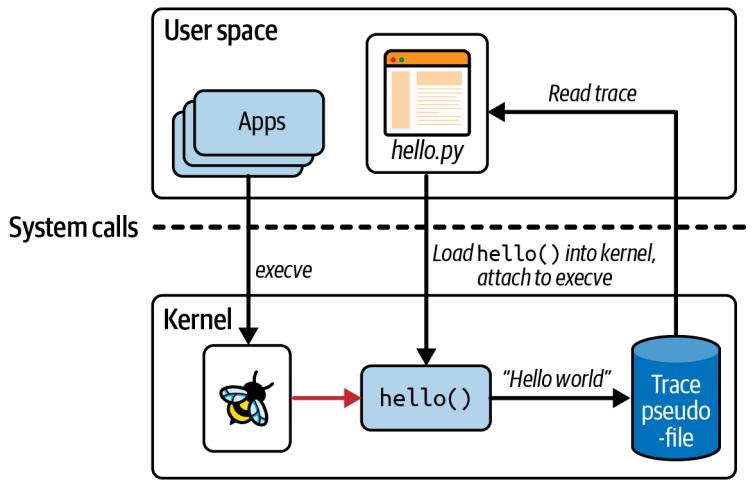
2.2 Running “Hello World”
由于 eBPF 非常强大,因此需要特殊权限才能使用它。权限会自动分配给 root 用户,因此最简单的方法是以 root 身份运行 eBPF 程序,或使用 sudo 命令。
1 | $ ./hello.py |
- eBPF 程序可用于动态更改系统行为。无需重新启动机器或重启现有进程。eBPF 代码一旦附加到事件上,就会立即生效。
- 无需更改其他应用程序,即可使它们对 eBPF 可见。
2.3 BPF Maps
一个更好的从 eBPF 程序中获取信息的方法。
map 可以用于在多个 eBPF 程序之间共享数据,或在用户空间应用程序与内核中运行的 eBPF 代码之间进行通信。
典型的用途包括:
- 用户空间向 eBPF 程序写入待其获取的配置信息
- eBPF 程序存储状态,以供另一个 eBPF 程序(或同一程序后续运行时)调取
- eBPF 程序将结果或指标写入 map,供用户空间应用调取并展示结果
2.3.1 BPF Maps 类型定义
- BPF_MAP_TYPE_HASH
- BPF_MAP_TYPE_ARRAY
针对特定类型的操作进行了优化:
- BPF_MAP_TYPE_QUEUE: 先进先出 队列
- BPF_MAP_TYPE_STACK: 先进后出 栈
- BPF_MAP_TYPE_LRU_HASH: LRU 最近最少使用
- BPF_MAP_TYPE_LRU_PERCPU_HASH: precpu
- BPF_MAP_TYPE_LPM_TRIE: 最长前缀匹配
- BPF_MAP_TYPE_BLOOM_FILTER: 布隆过滤器 (一种概率数据结构,旨在提供非常快速的元素存在性检查)
保存特定类型对象的信息:
- BPF_MAP_TYPE_SOCKMAP:保存有关套接字的信息,并被网络相关的 eBPF 程序用来重定向流量
- BPF_MAP_TYPE_DEVMAP:保存有关网络设备的信息,并被网络相关的 eBPF 程序用来重定向流量
存储一组索引的 eBPF 程序:
- BPF_MAP_TYPE_PROG_ARRAY:用于实现尾调用(tail calls),即一个程序可以调用另一个程序
存储关于 map 的信息:
- BPF_MAP_TYPE_ARRAY_OF_MAPS
- BPF_MAP_TYPE_HASH_OF_MAPS
per-cpu 版本:
- BPF_MAP_TYPE_PERCPU_HASH
- BPF_MAP_TYPE_PERCPU_ARRAY: 每个 CPU 核心对于该 map 都有各自的版本,并且内核使用不同的内存块来存储它们。
内核文档中的相关信息:
2.3.2 Hash Table Map
示例 [hello-map.py]:显示不同用户运行程序的次数。
1 | // 定义一个 hash table map |
你可能会注意到代码中的这两行并不是标准的 c 代码,
1 | p = counter_table.lookup(&uid); |
BCC 的 C 版本实际上是一种类 C 语言,BCC 在将代码发送到编译器之前会对其进行重写。
与 hello.py 不同的地方:
1 | while True: |
运行:
1 | $ ./hello-map.py |
1 | $ ls |
2.3.2 Perf and Ring Buffer Maps
Perf Maps
示例 [hello-buffer.py]:
1 | BPF_PERF_OUTPUT(output); |
1 | b = BPF(text=program) |
运行:
1 | $ ./hello-buffer.py |
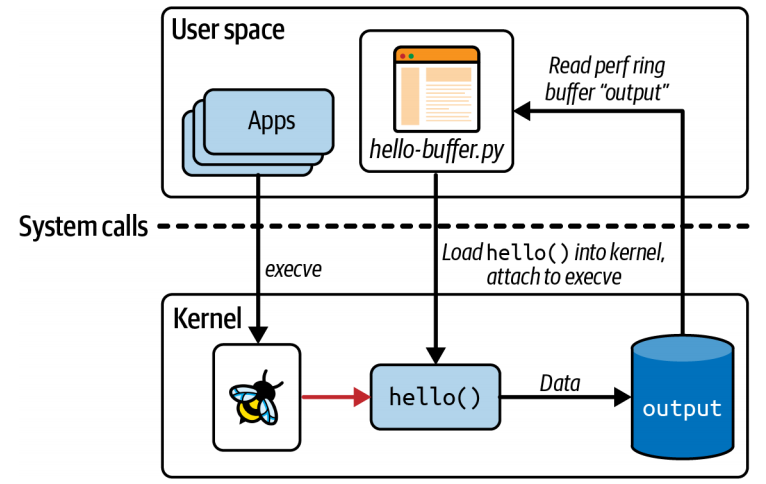
程序类型和触发事件的类型决定了可用的上下文(context)信息集合以及可用于检索信息的有效辅助函数集合。
上下文信息的可用性使得 eBPF 代码在可观测性方面极具价值。每当事件发生时,eBPF 程序不仅可以报告事件发生的事实,还可以报告触发事件的相关信息。由于所有这些信息都可以在内核内收集,而无需同步上下文切换到用户空间,因此性能也非常高。
Ring Buffer
内核版本 5.8 及以上。
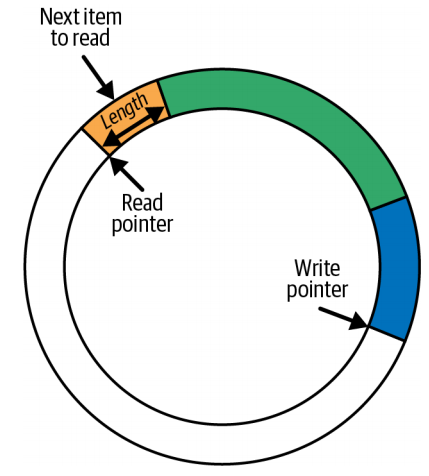
环形缓冲区 (Ring Buffer) 并不是 eBPF 独有的。
可以将环形缓冲区想象为一个环形的内存片段,具有独立的写指针(write pointer)和读指针(read pointer)。
写操作:
- 任意长度的数据从写指针(write pointer)所在的位置写入,数据的长度信息包含在该数据的头部中。
- 写指针(write pointer)移动到该数据的末尾,为下一次写操作做准备。
读操作:
- 数据从读指针(read pointer)所在的位置开始读取,使用头部的信息来确定要读取的长度。
- 读指针(read pointer)指向下一个可用的数据片段。
- 读指针(read pointer)与写指针(write pointer)沿着相同的方向移动。
如果读指针(read pointer)追上了写指针(write pointer),表示没有数据可读。
如果写操作会使写指针(write pointer)超过读指针(read pointer),数据将不会被写入,并且 drop counter 会增加。读操作会同时读取 drop counter 来查看自上次成功读取以来是否有数据丢失。
相关阅读:
2.3.3 Function Calls
在早期,eBPF 程序不允许调用辅助函数以外的其他函数。为了解决这个问题,程序员通常会指示编译器始终内联(always inline)他们的函数,如下所示:
1 | static __always_inline void my_function(void *ctx, int val) |
如图,右侧显示了内联函数时的情况:没有跳转指令;相反,在调用函数内直接包含函数的指令副本。
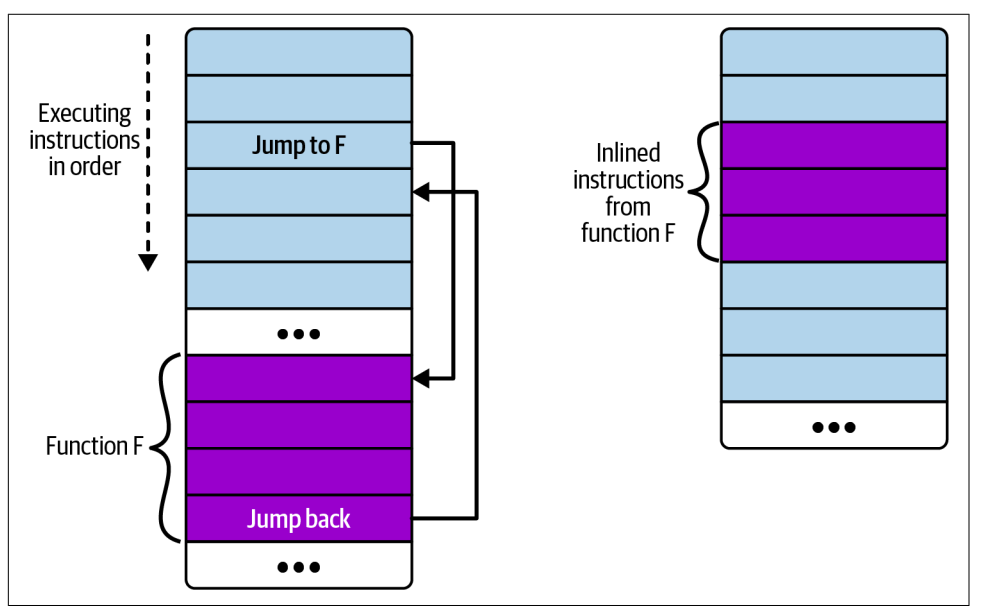
有时编译器可能会出于优化目的,选择内联一个函数。这也是为什么可能无法附加 kprobe 到某些内核函数的原因之一。
从 Linux 内核 4.16 和 LLVM 6.0 开始,解除了需要将函数内联的限制,以便 eBPF 程序员可以更自然地编写函数调用。
2.3.4 Tail Calls
eBPF 中的另一种将复杂功能拆分为更小模块的机制:尾调用。
正如 ebpf.io 所描述的那样,“尾调用可以调用并执行另一个 eBPF 程序,并替换执行上下文(context),类似于 execve() 系统调用对常规进程的操作。” 换句话说,尾调用完成后执行不会返回给调用者。
尾调用绝不仅仅限于 eBPF 编程。尾调用的总体动机是避免在函数递归调用时一遍又一遍地增加栈帧,最终可能导致栈溢出错误。尾调用允许调用一系列函数而不增加栈。这在 eBPF 中特别有用,因为栈被限制为 512 字节。
尾调用使用 bpf_tail_call() 辅助函数来完成,其签名如下:
1 | long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index) |
ctx: 将上下文从主动发起函数调用的 eBPF 程序段传递给被调用的目标程序。prog_array_map: 一个BPF_MAP_TYPE_PROG_ARRAY类型的 eBPF map,用于保存一组文件描述符,这些描述符用于标识 eBPF 程序。index: 应调用该组 eBPF 程序中的哪个程序。
这个辅助函数的特别之处在于:如果它成功执行,将永远不会返回。当前运行的 eBPF 程序的栈会被被调用的程序替换。如果指定的程序不存在于 map 中,则可能会失败。在这种情况下,调用程序会继续执行。
用户态代码必须将所有 eBPF 程序加载到内核中(与常规操作一致),同时还需完成程序数组映射(prog_array_map)的初始化配置。
示例 [hello-tail.py]:
1 | // 定义一个名称为 syscall ,类型为 BPF_MAP_TYPE_PROG_ARRAY 的 eBPF map,可容纳 500 个元素 |
用户空间代码(user space code):
1 | b = BPF(text=program) |
运行:
1 | $ ./hello-tail.py |
自内核版本 4.2 起,eBPF 开始支持尾调用,但在很长一段时间内,尾调用与 BPF 到 BPF 函数调用(BPF to BPF function calls)是不兼容的。这一限制在内核版本 5.10 中被解除。
尾调用最多可以链式组合达到 33 次,每个 eBPF 程序的指令复杂度限制为 100 万条指令。
2.4 Summary
“extended” BPF 区别于 BPF 的几个特征:
辅助函数 (helper funciton)
BPF map
尾调用:
- 尾调用使用
bpf_tail_call()辅助函数来完成,如果它成功执行,将永远不会返回。 - 当前运行的 eBPF 程序的栈会被被调用的程序替换。
- 如果指定的程序不存在于 map 中,则可能会失败。在这种情况下,调用程序会继续执行。