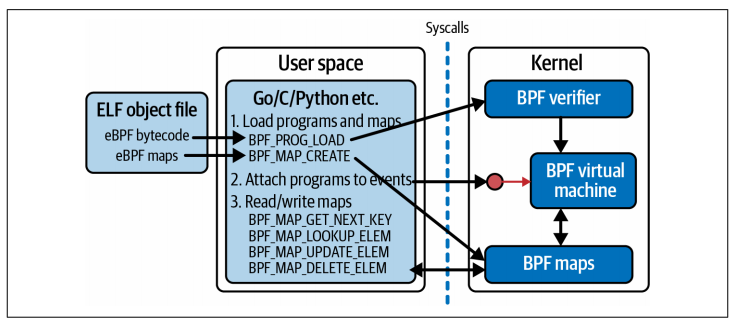
如果用户空间应用程序 (user space application) 想将 eBPF 程序加载到内核中,必然会涉及到一些系统调用,这个系统调用是 bpf()。系统调用接口仅供用户空间应用程序使用。
运行在内核中的 eBPF 代码并不使用系统调用 (syscalls) 来访问映射 (maps)。eBPF 程序使用辅助函数 (helper functions) 来读写映射 (maps)。
如果你之后自己编写 eBPF 程序,大概率不需要直接调用这些 bpf() 系统调用。在后续内容中介绍了一些库,它们提供了更上层的抽象封装,能简化开发流程。
这些抽象封装基本都是直接对应你将在本章中看到的底层系统调用命令。无论你使用哪一个库,都需要掌握本章会介绍的底层操作 —— 比如加载程序、创建并访问映射等等。
查看 man 手册 可以看到 bpf() 被用来在 eBPF 映射 (map) 或程序上执行命令。其函数签名如下:
1 | int bpf(int cmd, union bpf_attr *attr, unsigned int size); |
cmd, 要执行的命令attr, 指定命令参数所需的全部数据size,attr中数据的字节长度
示例 [hello-bufer-config.py]
1 | struct user_msg_t { |
在 python 代码中,在 config 哈希表中定义了用户 ID 0 和 1000 的消息,它们对应于该虚拟机上的 root 用户 ID 和我的用户 ID。
1 | b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!") |
$ id
运行:
1 | $ ./hello-buffer-config.py |
1 | $ ls |
查看程序运行时使用的 bpf() 系统调用:
1 | $ strace -e bpf ./hello-buffer-config.py |
4.1 Loading BTF Data
- cmd:
BPF_BTF_LOAD
1 | bpf(BPF_BTF_LOAD, {btf="\237\353\1\0"... }, 32) = 3 |
- 将一块 BTF 数据加载到内核中
bpf()系统调用的返回值(在我的示例中为 3)是引用该数据的文件描述符
如果使用的 Linux 内核版本较低,可能看不到这个命令。这与 BTF ( BPF Type Format) 有关,这一特性在 Linux 内核版本 5.1 被引入。
BTF 可以让 eBPF 程序跨不同内核版本进行移植,你可以在一台机器上编译程序,然后在另一台机器上使用它,哪怕这台机器运行的是不同的内核版本,对应拥有不同的内核数据结构。
4.2 Creating Maps
- cmd:
BPF_MAP_CREATE:创建一个 eBPF map
1 | bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_PERF_EVENT_ARRAY, key_size=4, |
- 类型为
BPF_MAP_TYPE_PERF_EVENT_ARRAY,名为output - key 和 vlaue 的长度都为 4 字节
1 | bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, |
- 类型为
BPF_MAP_TYPE_HASH,名为config - key 的大小为 4 字节,value 的大小为 13 字节
- 没有指定该 table 的大小,但 BCC 默认大小为 10240
btf_fd=3,告诉内核使用之前获得的 BTF 文件描述符 3。 BTF 信息描述了数据结构的布局,将其包含在映射定义中意味着拥有关于映射中使用的键和值类型布局的信息。
4.3 Loading a Program
通过以下 bpf() 系统调用将 eBPF 程序加载到内核中
1 | bpf(BPF_PROG_LOAD, {prog_type=BPF_PROG_TYPE_KPROBE, insn_cnt=47, |
prog_type: eBPF 程序的类型为BPF_PROG_TYPE_KPROBEinsn_cnt: 程序中字节码指令的数量。insns: 构成这个 eBPF 程序的字节码指令在内存中的地址。license: GPL 许可prog_name: eBPF 程序的名字为 helloexpected_attach_type:BPF_CGROUP_INET_INGRESS恰好是 BPF 附加类型列表中的第一个,它的值为 0prog_btf_fd: 告知内核,该程序要使用此前加载的哪一段 BTF 数据块。此处的数值 3 对应之前看到的、由BPF_BTF_LOAD系统调用返回的文件描述符
如果程序验证失败,这个系统调用会返回负值。
4.4 Modifying a Map from User Space
1 | b["config"][ct.c_int(0)] = ct.create_string_buffer(b"Hey root!") |
可以看到这些条目被通过如下系统调用,在 map 中定义:
1 | bpf(BPF_MAP_UPDATE_ELEM, {map_fd=5, key=0x7408c92a9020, value=0x7408c92a8520, |
BPF_MAP_UPDATE_ELEM命令用于更新 map 中的键值对BPF_ANY: 表示如果 key 在 map 中不存在,则创建它map_fd: 正在操作的 map 的文件描述符
文件描述符是由内核为特定进程分配的,所以这个值 5 只对该特定用户空间进程有效。访问内核中同一映射(map)结构的两个用户态程序,所被分配的文件描述符数值很可能不同;同理,两个用户态程序也可能针对完全不同的映射(map),拥有相同的文件描述符数值。
使用 bpftool 查看 map 的内容:
1 | bpftool map dump name config |
1 | [{ |
bpftool 是怎么知道如何格式化输出的呢?答案是,它会使用在定义该映射(map)的 BPF_MAP_CREATE 系统调用中所包含的 BTF 信息里的定义。
4.5 BPF Program and Map References
- 引用计数
当停止运行程序后会发生什么?你会发现程序和映射 (maps) 会被自动卸载 (unloaded),出现这种情况的原因是内核会通过引用计数 (reference counts) 对它们进行追踪管理。
通过 bpf() 系统调用将 BPF 程序加载到内核中会返回一个文件描述符。在内核中,这个文件描述符是该程序的一个引用。发起这个系统调用的用户态进程拥有这个文件描述符;当该进程退出时,文件描述符会被释放,程序的引用计数会递减。当一个 BPF 程序的引用计数归零时,内核就会移除该程序。
4.5.1 Pinning
eBPF program
当将程序固定(pinning)到文件系统时,会创建一个额外的引用。因此该程序会在命令执行完成后仍保持加载状态。
1 | bpftool prog load hello.bpf.o /sys/fs/bpf/hello |
这些被固定的对象并非是持久化存储到磁盘的真实文件,它们创建于一个伪文件系统之上,这个伪文件系统的行为与基于磁盘的常规文件系统类似,也具备目录和文件的结构。但这些对象都存储在内存中,这意味着系统重启之后它们就不会再保留在原来的位置。
当 BPF 程序被挂载到一个会触发它的钩子 (hook) 上时,引用计数器也会递增。引用计数的行为依赖于 BPF 的程序类型。
- 与追踪 (tracing) 相关(比如 kprobes 和 tracepoints)的类型,与一个用户态进程相关联(当对应的进程退出时,内核的引用计数就会递减)
- 附加到网络协议栈或 cgroups (control groups) 类型的程序,不与任何用户态进程相关联,即使加载它们的用户态程序退出 (exits) 了,它们仍会保留在原有位置。
如,使用 ip link 命令加载一个 XDP 类型的程序:
1 | ip link set dev eth0 xdp obj hello.bpf.o sec xdp |
可以看到当命令执行完成后,使用 bpftool 仍然可以看到加载到内核中的 XDP 程序。
1 | $ bpftool prog list |
eBPF map
eBPF maps 同样拥有引用计数器,当它们的引用计数降至零时,就会被清理掉。
eBPF 程序的源代码有可能会定义一个程序实际并未引用的映射。此时程序不会自动对该映射生成引用计数。
BPF(BPF_PROG_BIND_MAP)系统调用,可以将一个映射与一个程序进行关联,这样一来,就算加载程序的用户态进程退出、不再持有该映射的文件描述符引用,这个映射也不会被立即清理。
映射也可以被固定到文件系统中,用户态程序可以通过该映射的路径来获取对它的访问权限。
相关阅读:
4.5.2 BPF Links
创建 BPF 程序引用的另一种方式。
BPF 链接为 eBPF 程序与其附加的事件之间提供了一个抽象层。BPF 链接本身可以被固定到文件系统中,这为程序创建了另一个引用。这意味着将程序加载到内核的用户空间进程可以终止,而程序仍然被加载。用户空间加载程序的文件描述符被释放,减少了程序的引用计数,但由于 BPF 链接的存在,引用计数将不为零。
本章结尾的练习中将看到 BPF 链接的实际应用。
4.6 Additional Syscalls Involved in eBPF
strace 输出中接下来显示的内容与设置 perf buffer 有关。
4.6.1 Initializing the Perf Bufer
1 | bpf(BPF_MAP_UPDATE_ELEM, {map_fd=4, key=0x770d75d708a0, value=0x770d75d70520, |
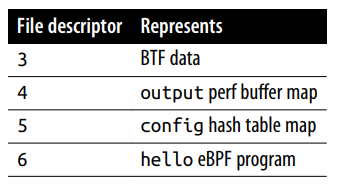
映射的文件描述符是 4,它代表 output perf 缓冲区映射 (buffer map)。
使用 strace 运行此示例时,显示更多系统调用:
1 | strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py |
4.6.2 Attaching to Kprobe Events
当 eBPF 程序 hello 被加载到内核中后,系统分配了文件描述符 6 来表示它。要将这个 eBPF 程序挂载到某个事件上,还需要一个代表该特定事件的文件描述符。
以下是 strace 输出中的一行内容,展示了为 execve() kprobe 创建文件描述符的过程:
1 | perf_event_open({type=0x8 /* PERF_TYPE_??? */, ...}, ...) = 7 |
根据 main 手册 ,调用 perf_event_open() 会创建一个文件描述符,该文件描述符可用于测量性能信息。
从输出可以看到,strace 无法解释值为 8 的类型参数,但如果进一步查看手册,会发现 Linux 如何支持性能测量单元(Performance Measurement Unit)的动态类型:
1 | $ cat /sys/bus/event_source/devices/kprobe/type |
perf_event_open() 的返回码是 7,这代表 kprobe 的 perf 事件的文件描述符,并且文件描述符 6 代表的是 eBPF 程序 hello。在 main 手册 中还解释了如何使用 ioctl() 在这两者之间创建关联:
- PERF_EVENT_IOC_SET_BPF: 此操作允许将 BPF 程序挂载到已有的 kprobe 追踪点事件上。其参数为一个 BPF 程序文件描述符。
这解释了您将在 strace 输出中看到的以下 ioctl() 系统调用,其中的参数指的是两个文件描述符:
1 | ioctl(7, PERF_EVENT_IOC_SET_BPF, 6) = 0 |
还有一个 ioctl() 调用用来启动 kprobe 事件:
1 | ioctl(7, PERF_EVENT_IOC_ENABLE, 0) = 0 |
完成此设置后,只要这台机器上运行 execve(),就会触发这个 eBPF 程序。
4.6.3 Setting Up and Reading Perf Events
看到与 output perf 缓冲区相关的 bpf(BPF_MAP_UPDATE_ELEM) 调用重复出现几次与使用的处理器的核心数量有关。
1 | perf_event_open({type=PERF_TYPE_SOFTWARE, size=0 /* PERF_ATTR_SIZE_??? */, |
在上面的输出中,使用 X 的位置表示值 0、1、2 和 3 。查阅 main 手册 会看到这是 cpu,它前面的字段是 pid 或进程 ID。
当 pid == -1 且 cpu >= 0 时,会测量指定 CPU 上所有的进程/线程。
这个过程会发生四次,与使用的笔记本电脑有四个 CPU 核心的情况相对应。
- 这终于解释了为什么 “output” 性能事件缓冲区映射中有四个条目:每个 CPU 核心对应一个条目。
- 这也解释了映射类型名称 BPF_MAP_TYPE_PERF_EVENT_ARRAY 中的 “array(数组)” 部分 —— 因为这个映射并非只代表一个性能事件环形缓冲区,而是一个缓冲区数组,每个核心对应一个缓冲区。
perf_event_open() 的每次调用都会返回一个文件描述符,将其表示为 Y;这些文件描述符的值分别为 8、9、10 和 11。
ioctl ()系统调用会为每一个这类文件描述符启用性能事件输出。
BPF_MAP_UPDATE_ELEM 类型的 bpf() 系统调用会设置映射条目,使其指向每个 CPU 核心的性能事件环形缓冲区,以此指定该核心可以提交数据的位置。
用户空间代码可以在这四个输出流文件描述符上使用 ppoll(),以便无论哪个核心恰好运行给定 execue() kprobe 事件的 eBPF 程序 hello,它都可以获得数据输出。
以下是 ppoll() 的系统调用:
1 | ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN}, |
注:
我在运行 strace -e bpf,perf_event_open,ioctl,ppoll ./hello-buffer-config.py 时,并没有看到 ppoll 的相关调用。在将 ppoll 改为 poll 后,可以看到如下系统调用:
1 | poll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, ...], 22, -1) |
4.7 Ring Bufers
在内核版本 5.8 及以上,相比于性能事件缓冲区 (perf buffer),更倾向于使用 BPF 环形缓冲区 (ring buffer)。这一方面是出于性能考量,另一方面也是为了确保数据的顺序性不会被打乱 —— 即便这些数据是由不同的 CPU 核心提交的。环形缓冲区的实现形式为单个缓冲区,供所有核心共享使用。
示例 [hello-ring-buffer-config.py]:

创建 output 环形缓冲区映射的 bpf() 系统调用如下所示:
1 | bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_RINGBUF, key_size=0, value_size=0, |
在撰写本文时,BCC 使用在前面展示的 ppoll 机制来处理 perf 缓冲区,但它使用较新的 epoll 机制来等待环形缓冲区的数据。
ppoll
[hello-buffer-config.py] 中产生的 ppoll() 系统调用如下:
1 | ppoll([{fd=8, events=POLLIN}, {fd=9, events=POLLIN}, {fd=10, events=POLLIN}, |
需要注意的是,这里传入了一组文件描述符(8、9、10、11),用户态进程正是要从这些描述符中读取数据。每当这个 poll 事件返回数据时,都必须再次调用 ppoll(),重新传入这同一组文件描述符。而在使用 epoll 时,这组文件描述符会由一个内核对象来管理。
epoll
当使用 strace 运行 [hello-ring-buffer-config.py] 时,会看到如下 epoll 相关的系统调用:
首先,用户空间程序请求在内核中创建一个新的 epoll 实例:
1 | epoll_create1(EPOLL_CLOEXEC) = 8 |
随后会调用 epoll_ctl(),该函数会告知内核,将文件描述符 4(即 output 缓冲区)添加到这个 epoll 实例所管理的文件描述符集合中。
1 | epoll_ctl(8, EPOLL_CTL_ADD, 4, {events=EPOLLIN, data={u32=0, u64=0}}) = 0 |
用户态程序调用 epoll_wait() 等待环形缓冲区中出现可用数据。只有当数据就绪时,该调用才会返回。
1 | epoll_wait(8, [{events=EPOLLIN, data={u32=0, u64=0}}], 1, -1) = 1 |
4.8 Reading Information from a Map
对 bpftool 行为的分析展示了用户空间程序如何遍历可用的映射以及存储在映射中的键值对。
以下命令展示了 bpftool 在读取 config 映射内容时,所调用的 bpf() 系统调用的片段:
1 | strace -e bpf bpftool map dump name config |
你将会看到,该流程包含两个主要步骤:
遍历所有映射,查找名称为
config的映射。若找到匹配的映射,则遍历该映射内的所有元素。
4.8.1 Finding a Map
bpftool 会遍历所有映射,查找名称为 config 的映射:
1 | bpf(BPF_MAP_GET_NEXT_ID, {start_id=0, ...}, 12) = 0 |
BPF_MAP_GET_NEXT_ID用于获取在start_id指定的值之后的下一个映射的 ID。BPF_MAP_GET_FD_BY_ID会返回指定映射 ID 对应的文件描述符。BPF_OBJ_GET_INFO_BY_FD用于获取由文件描述符所指向的对象(此处即映射)的相关信息。这些信息包含该对象的名称,bpftool可以据此判断该对象是否为其要查找的映射。
内核中加载的每个映射,都会对应这样一组三条系统调用。你还会发现,start_id 和 map_id 所使用的值,与这些映射的 ID 是相匹配的。当再也没有可供查找的映射时,这个重复的调用模式便会终止,此时 BPF_MAP_GET_NEXT_ID 会返回 ENOENT 错误值,如下所示:
1 | bpf(BPF_MAP_GET_NEXT_ID, {start_id=37, next_id=0, open_flags=0}, 12) = -1 ENOENT (No such file or directory) |
4.8.2 Reading Map Elements
如果找到了匹配的映射,bpftool 会持有该映射的文件描述符,以便从中读取元素。下面我们来看读取该信息对应的系统调用序列:
1 | bpf(BPF_MAP_GET_NEXT_KEY, {map_fd=3, key=NULL, next_key=0x5897d6dd81c0}, 24) = 0 |
首先,应用程序需要找到一个存在于该映射中的有效键 (key)。它通过
bpf()系统调用的BPF_MAP_GET_NEXT_KEY类型来实现这一操作。其中,key参数是一个指向键的指针,该系统调用会返回此键之后的下一个有效键。若传入的是一个空指针(NULL),则表示应用程序请求获取该映射中的第一个有效键。内核会将这个键写入到next_key指针所指向的内存地址中。BPF_MAP_LOOKUP_ELEM:给定一个键后,应用程序会请求获取其对应的数值,该数值会被写入 value 指针所指定的内存地址中。bpftool获取到第一组键值对的内容,并将该信息输出到屏幕上。当再次调用
BPF_MAP_GET_NEXT_KEY时,系统会返回ENOENT错误码,表明该映射中已无更多条目。最后,
bpftool完成屏幕输出的收尾工作并退出。
4.9 Summary
BPF_PROG_LOAD 和 BPF_MAP_CREATE
eBPF 程序和 maps 的引用计数 (reference counts)
BPF links
用户空间程序使用
perf_event_open()和ioctl()将 eBPF 程序附加到kprobe事件如何使用
BPF_MAP_GET_NEXT_ID、BPF_MAP_GET_FD_BY_ID和BPF_OBJ_GET_INFO_BY_FD来定位内核持有的映射和其他对象