CO-RE: compile once, run everywhere
BTF: BPF Type Format
许多 eBPF 程序都会访问内核数据结构,因此 eBPF 程序员需要引入相关的 Linux 头文件,才能让自己的 eBPF 代码正确定位这些数据结构中的字段。但 Linux 内核始终处于持续开发状态,这意味着内核内部的数据结构可能会在不同内核版本之间发生变化。
BTF (BPF Type Format) 是 BPF 技术 “一次编译,处处运行”(CO-RE) 方案的核心组成部分,该方案专门解决 eBPF 程序在不同内核版本间移植的难题。
CO-RE 方案允许 eBPF 程序内置其编译时所基于的数据结构布局信息,并提供了一套适配机制 —— 当程序运行的目标机器上的数据结构布局与编译时存在差异时,该机制可自动调整字段的访问方式。只要程序不会试图访问目标内核中根本不存在的字段或数据结构,它就能在不同的内核版本间实现跨版本兼容运行。
5.1 BCC’s Approach to Portability
为解决跨内核版本的可移植性问题,BCC 采用了在目标机器上实时编译 eBPF 代码的方案。
这样的方案存在很多问题:
你需要在所有希望运行代码的目标机器上安装编译工具链,同时还得安装内核头文件(这类文件在默认情况下并非总会预装)。
工具启动前,必须等待编译完成,这意味着每次启动工具时,都可能产生数秒的延迟。
如果要在一大批配置相同的机器上运行这款工具,那么在每台机器上重复执行编译操作,会造成计算资源的浪费。
部分基于 BCC 构建的项目会将自身的 eBPF 源代码与工具链打包成容器镜像,这种方式能更便捷地将程序分发到每台目标机器。但这并不能解决内核头文件的预装问题,甚至可能导致新的问题 —— 如果在同一台机器上安装了多个这类 BCC 容器,会造成更多的资源冗余。
嵌入式设备则可能没有足够的内存资源来完成编译步骤。
5.2 CO-RE Overview
BTF
- BTF 是一种用于描述数据结构布局与函数签名的格式。在 CO-RE 技术中,它被用来判断编译期与运行期所使用的数据结构之间存在的任何差异。
bpftool这类工具也会借助 BTF,以人类可读的格式导出数据结构。- Linux 5.4 及以上版本的内核均支持 BTF 格式。
Kernel headers
- Linux 内核源代码中包含用于描述其所用数据结构的头文件,且这些头文件的内容会随 Linux 版本的更迭发生变化。
- eBPF 程序员既可以选择引入单个头文件,也可以借助
bpftool工具从运行中的系统生成一个名为vmlinux.h的头文件 —— 该文件包含了 eBPF 程序可能需要的、关于当前内核的所有数据结构信息。
Compiler support
- 使用 Clang 编译器通过
-g编译选项编译 eBPF 程序时,会自动嵌入一种名为 CO-RE 重定位信息 的内容,这类信息衍生自用于描述内核数据结构的 BTF 信息。 - GCC 编译器也在其 12 版本中,新增了针对 BPF 目标程序的 CO-RE 支持功能。
- 使用 Clang 编译器通过
Library support for data structure relocations
- 在用户态程序将 eBPF 程序加载至内核时,CO-RE 方案要求根据编译到目标文件中的 CO-RE 重定位信息,对字节码进行调整,以补偿程序编译时所基于的数据结构,与即将运行的目标机器上的数据结构之间存在的任何差异。
libbpf是最早具备该重定位能力的 C 语言类库 (自动完成)- Cilium eBPF 类库为 Go 语言开发者提供了相同的功能
- Aya 则面向 Rust 语言实现了该特性。
Optionally, a BPF skeleton
- 可以从已编译的 BPF 目标文件中自动生成一个骨架文件 (skeleton),该文件包含若干便捷函数,用户态代码可调用这些函数来管理 BPF 程序的生命周期 —— 包括将程序加载至内核、挂载到事件上等操作。
- 如果用户态代码使用 C 语言编写,可通过
bpftool gen skeleton命令生成该骨架文件。 - 这些函数属于更上层的抽象封装,相比直接调用底层类库(如 libbpf、cilium/ebpf 等),能为开发者带来更高的开发效率。
相关阅读:
5.3 BPF Type Format
BTF 信息描述了数据结构 (data structures) 与代码 (code) 在内存中的布局方式。
5.3.1 BTF Use Cases
本章在讲解 CO-RE 技术时引入 BTF 相关内容,核心原因在于:掌握 eBPF 程序编译时所基于的数据结构布局,与即将运行的目标环境中的数据结构布局之间的差异,能够让程序在加载至内核的过程中,完成对应的适配调整。
bpftool 工具借助 BTF 信息,对映射导出(map dump)的输出内容进行格式化处理
BTF 信息还包含行号与函数信息,这让 bpftool 工具能够在反编译或即时编译(JIT)后的程序导出内容中,穿插显示对应的源代码。 (Chapter 3)
源代码信息被穿插显示在验证器 (verifier) 日志输出中 —— 而这些信息同样来自于 BTF 数据。(Chapter 6)
BPF 自旋锁 (spin locks) 的实现同样需要依赖 BTF 信息。
- 该锁必须作为映射值结构的一部分,示例如下:
1 | struct my_value { |
在内核中,eBPF 程序通过 bpf_spin_lock() 和 bpf_spin_unlock() 这两个辅助函数来获取和释放自旋锁。只有当存在能够描述锁字段在结构体中位置的 BTF 信息时,才能调用这些辅助函数。
自旋锁功能在 5.1 版本内核中被引入。使用自旋锁存在诸多限制:它仅适用于哈希(hash)或数组(array)类型的映射,且不能在跟踪(tracing)或套接字过滤器(socket filter)类型的 eBPF 程序中使用。
相关阅读:
5.3.2 Listing BTF Information with bpftool
列出内核中加载的所有 BTF data:
1 | bpftool btf list |
1 | 1: name [vmlinux] size 6050732B |
列表中的第一项是 vmlinux,它对应于之前提到的承载当前运行内核 BTF 信息的 vmlinux 文件。
示例:
1 | $ cd learning-ebpf/chapter4 |
1 | $ bpftool btf list |
- 这段 BTF 信息块的 ID 为 100
- 这是一块大小约 2KB 的匿名 BTF 信息数据块。
- 它被程序 ID 为 123 的 BPF 程序,以及映射 ID 为 70 的 BPF 映射所使用。
1 | $ bpftool prog show name hello |
5.3.3 BTF Types
知道该 BTF 信息的 ID,就可以通过命令 bpftool btf dump id <id> 来查看它的内容。
$ bpftool btf dump id 100
[1] TYPEDEF ‘u32’ type_id=2
[2] TYPEDEF ‘__u32’ type_id=3
[3] INT ‘unsigned int’ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[4] STRUCT ‘user_msg_t’ size=13 vlen=1
‘message’ type_id=6 bits_offset=0
[5] INT ‘char’ size=1 bits_offset=0 nr_bits=8 encoding=SIGNED
[6] ARRAY ‘(anon)’ type_id=5 index_type_id=7 nr_elems=13
[7] INT ‘ARRAY_SIZE_TYPE‘ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[8] STRUCT ‘____btf_map_config’ size=20 vlen=2
‘key’ type_id=1 bits_offset=0
‘value’ type_id=4 bits_offset=32
[9] INT ‘(anon)’ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[10] PTR ‘(anon)’ type_id=0
[11] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=1
‘ctx’ type_id=10
[12] INT ‘int’ size=4 bits_offset=0 nr_bits=32 encoding=SIGNED
[13] FUNC ‘hello’ type_id=11 linkage=static
[14] INT ‘(anon)’ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[15] STRUCT ‘config_table_t’ size=160 vlen=20
‘key’ type_id=1 bits_offset=0
‘leaf’ type_id=4 bits_offset=32
‘lookup’ type_id=16 bits_offset=192
‘lookup_or_init’ type_id=20 bits_offset=256
‘lookup_or_try_init’ type_id=20 bits_offset=320
‘update’ type_id=22 bits_offset=384
‘insert’ type_id=22 bits_offset=448
‘delete’ type_id=24 bits_offset=512
‘call’ type_id=26 bits_offset=576
‘increment’ type_id=28 bits_offset=640
‘atomic_increment’ type_id=28 bits_offset=704
‘get_stackid’ type_id=30 bits_offset=768
‘sk_storage_get’ type_id=35 bits_offset=832
‘sk_storage_delete’ type_id=37 bits_offset=896
‘inode_storage_get’ type_id=35 bits_offset=960
‘inode_storage_delete’ type_id=37 bits_offset=1024
‘task_storage_get’ type_id=35 bits_offset=1088
‘task_storage_delete’ type_id=37 bits_offset=1152
‘max_entries’ type_id=1 bits_offset=1216
‘flags’ type_id=12 bits_offset=1248
[16] PTR ‘(anon)’ type_id=17
[17] FUNC_PROTO ‘(anon)’ ret_type_id=18 vlen=1
‘(anon)’ type_id=19
[18] PTR ‘(anon)’ type_id=4
[19] PTR ‘(anon)’ type_id=1
[20] PTR ‘(anon)’ type_id=21
[21] FUNC_PROTO ‘(anon)’ ret_type_id=18 vlen=2
‘(anon)’ type_id=19
‘(anon)’ type_id=18
[22] PTR ‘(anon)’ type_id=23
[23] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=2
‘(anon)’ type_id=19
‘(anon)’ type_id=18
[24] PTR ‘(anon)’ type_id=25
[25] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=1
‘(anon)’ type_id=19
[26] PTR ‘(anon)’ type_id=27
[27] FUNC_PROTO ‘(anon)’ ret_type_id=0 vlen=2
‘(anon)’ type_id=10
‘(anon)’ type_id=12
[28] PTR ‘(anon)’ type_id=29
[29] FUNC_PROTO ‘(anon)’ ret_type_id=0 vlen=2
‘(anon)’ type_id=1
‘(anon)’ type_id=0
[30] PTR ‘(anon)’ type_id=31
[31] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=2
‘(anon)’ type_id=10
‘(anon)’ type_id=32
[32] TYPEDEF ‘u64’ type_id=33
[33] TYPEDEF ‘__u64’ type_id=34
[34] INT ‘unsigned long long’ size=8 bits_offset=0 nr_bits=64 encoding=(none)
[35] PTR ‘(anon)’ type_id=36
[36] FUNC_PROTO ‘(anon)’ ret_type_id=10 vlen=3
‘(anon)’ type_id=10
‘(anon)’ type_id=10
‘(anon)’ type_id=12
[37] PTR ‘(anon)’ type_id=38
[38] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=1
‘(anon)’ type_id=10
[39] INT ‘(anon)’ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[40] STRUCT ‘output_table_t’ size=32 vlen=5
‘key’ type_id=12 bits_offset=0
‘leaf’ type_id=1 bits_offset=32
‘perf_submit’ type_id=41 bits_offset=64
‘perf_submit_skb’ type_id=43 bits_offset=128
‘max_entries’ type_id=1 bits_offset=192
[41] PTR ‘(anon)’ type_id=42
[42] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=3
‘(anon)’ type_id=10
‘(anon)’ type_id=10
‘(anon)’ type_id=1
[43] PTR ‘(anon)’ type_id=44
[44] FUNC_PROTO ‘(anon)’ ret_type_id=12 vlen=4
‘(anon)’ type_id=10
‘(anon)’ type_id=1
‘(anon)’ type_id=10
‘(anon)’ type_id=1
[45] INT ‘(anon)’ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[46] ARRAY ‘(anon)’ type_id=5 index_type_id=7 nr_elems=4
[47] INT ‘(anon)’ size=4 bits_offset=0 nr_bits=32 encoding=(none)
[48] PTR ‘(anon)’ type_id=0
[49] PTR ‘(anon)’ type_id=0
[50] PTR ‘(anon)’ type_id=0
[51] PTR ‘(anon)’ type_id=0
[52] PTR ‘(anon)’ type_id=0
[53] PTR ‘(anon)’ type_id=0
[54] PTR ‘(anon)’ type_id=0
[55] PTR ‘(anon)’ type_id=0
[56] PTR ‘(anon)’ type_id=0
[57] PTR ‘(anon)’ type_id=0
开头这几行的 BTF 信息,对应的是代码中定义的 config hash map,其源代码定义如下:
1 | struct user_msg_t { |
BTF 输出信息的前三行如下:
1 | [1] TYPEDEF 'u32' type_id=2 |
[1] 代表 type_id 1。
Type 1 定义了一个名为
u32的类型,而该类型的具体定义由type_id 2给出 —— 也就是以 [2] 开头的那一行所定义的类型。正如你所知,confighash map 中的键的类型正是u32。Type 2 的名为
__u32,类型由type_id 3给出Type 3 的名为
unsigned int,类型为整数 (INT), 大小为 4 字节。
这三种类型均为 32 位无符号整数类型的别名。在 C 语言中,整数类型的长度是与平台相关的,因此 Linux 内核定义了 u32 这类类型,用于显式指定特定长度的整数。在当前设备中,u32 对应的就是无符号整数类型。用户态代码中若要引用这类类型,应使用带双下划线前缀的别名,例如 __u32。
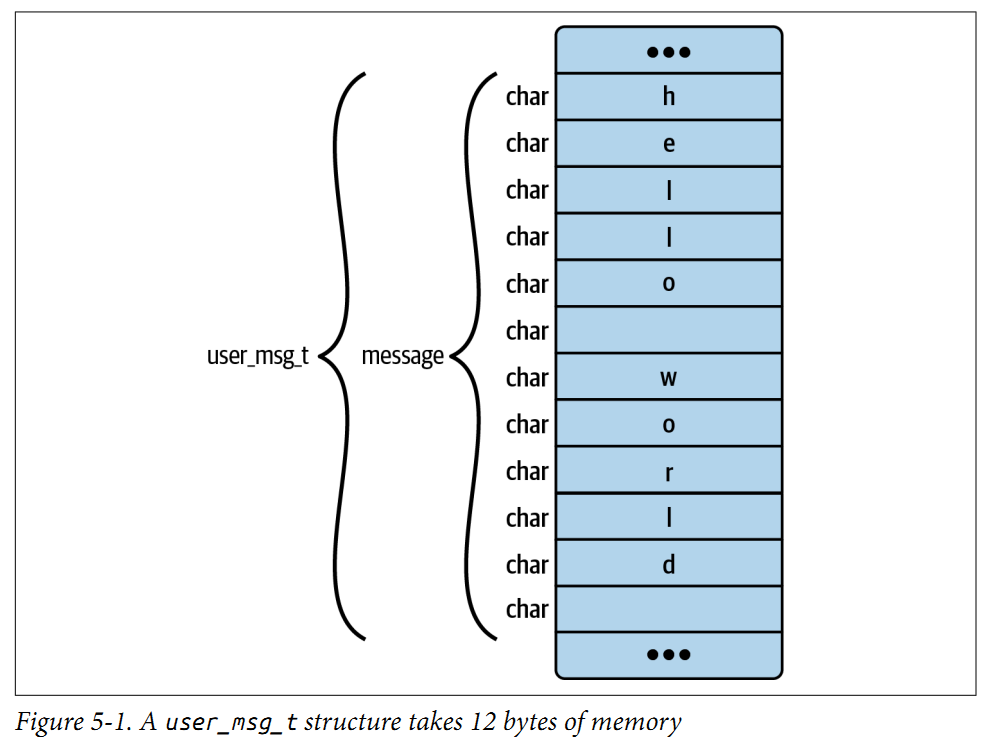
1 | [4] STRUCT 'user_msg_t' size=13 vlen=1 |
这些内容对应 config map 中用作值类型的 user_msg_t 结构体:
Type 4 就是
user_msg_t结构体本身,其总长度为 13 字节。该结构体包含一个名为message的字段,此字段由type_id 6定义。vlen字段表示该结构体定义中包含的字段数量。Type 5 命名为
char,是 1 字节长度的整数 —— 这完全符合 C 语言程序员对 char 类型的预期定义。Type 6 将
message字段的类型定义为一个包含 13 个元素的数组。数组中的每个元素类型为5(即 char 类型),且该数组的索引类型由type_id 7定义。Type 7 是 4 字节长度的整数
目前为止,所有条目均将 bits_offset 设为 0,但下一行输出则对应一个包含多个字段的结构体:
1 | [8] STRUCT '____btf_map_config' size=20 vlen=2 |
这是一个用于定义存储在名为 config 的映射中键值对的结构体定义。
我并未在源代码中自行定义 ____btf_map_config 这个类型,它是由 BCC 自动生成的。其中键的类型为 u32,值的类型则是 user_msg_t 结构体,这两种类型分别对应之前看到的 type 1 和 type 4。
关于该结构体的 BTF 信息中,还有一个关键内容:value 字段的起始位置相较于结构体起始地址偏移了 32 位。这完全符合逻辑,因为前 32 位的存储空间需要用来存放 key 字段。
5.3.4 Maps with BTF Information
在第四章中已经了解到,map 是通过 bpf(BPF_MAP_CREATE) 系统调用创建的。
1 | bpf(BPF_MAP_CREATE, {map_type=BPF_MAP_TYPE_HASH, key_size=4, value_size=13, max_entries=10240, map_flags=0, inner_map_fd=0, map_name="con |
该系统调用会接收一个 bpf_attr 结构体作为参数,这个结构体在内核中的定义如下(省略了部分细节):
1 | struct { /* anonymous struct used by BPF_MAP_CREATE command */ |
____btf_map_config 并未被内核用于 map 定义;它仅由 BCC 在用户空间使用。
5.3.5 BTF Data for Functions and Function Prototypes
BTF 数据还包含有关函数和函数原型的信息。
1 | [10] PTR '(anon)' type_id=0 |
Type 13 可以看到函数名为
hello,type_id为 11。Type 11 是一个函数原型,返回值类型为 type_id 12;一个名为
ctx的参数,type_id 为 10。Type 10 是一个匿名指针,type_id 为 0,它没有显式的包含在 BTF 输出中,但被定义为 void 类型。
encoding=SIGNED表示这是一个有符号的整数。
对应 hello-buffer-config.py 中的函数定义为:
1 | int hello(void *ctx) |
5.3.6 Inspecting BTF Data for Maps and Programs
查看与特定映射关联的 BTF 类型:
1 | $ bpftool btf dump map name config |
查看特定程序的 BTF 信息:
1 | $ bpftool btf dump prog id 123 |
参考:
5.4 Generating a Kernel Header File
1 | $ bpftool btf list |
列表中第一项的 ID 为 1、名称为 vmlinux,它是一份 BTF 信息,涵盖了当前(虚拟)机器上运行的内核所使用的所有数据类型、结构体以及函数定义。
通过 bpftool 工具能够从内核自带的 BTF 信息中,生成被命名为 vmlinux.h的头文件,你可以使用如下命令生成它:
1 | bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h |
当你将源码编译为 eBPF 目标文件时,该目标文件会包含一份与该头文件中所用定义相匹配的 BTF 信息。
后续在目标机器上运行该程序时,负责将程序加载至内核的用户态程序会自动进行适配调整,以消除编译期 BTF 信息与目标机器上运行内核的 BTF 信息之间的差异。
自 5.4 版本起,Linux 内核便已内置以 /sys/kernel/btf/vmlinux 文件形式存在的 BTF 信息。不过,也可以为旧版本内核生成可供 libbpf 调用的原始 BTF 数据。
若你希望在一台未预装 BTF 信息的目标机器上运行支持 CO-RE 特性的 eBPF 程序,可以自行为该目标机器提供对应的 BTF 数据。关于如何生成 BTF 文件的方法,以及适用于多种 Linux 发行版的 BTF 文件归档包,均可在 BTFHub 上获取。
5.5 CO-RE eBPF Programs
5.5.1 Header Files
hello-buffer-config.bpf.c 文件的前几行代码指定了该程序所需的头文件:
1 |
Kernel header information:
如果你要使用 libbpf 库中的任何 BPF 辅助函数,就需要引入 vmlinux.h 或 linux/types.h 头文件,以获取 u32、u64 等类型的定义 —— 这些类型是 BPF 辅助函数的源码会引用到的。
vmlinux.h 文件派生自内核源码头文件,但它并未包含这些头文件中通过 #define 定义的常量值。
例如,若你的 eBPF 程序需要解析以太网数据包,你很可能会用到一些常量定义 —— 这些常量用于标识数据包承载的协议类型(比如 0x0800 代表 IP 数据包,0x0806 代表 ARP 数据包)。如果不引入为内核定义了这些常量的 if_ether.h 文件,你就需要在自己的代码中手动复写这一系列常量值。
Headers from libbpf:
若要在你的 eBPF 代码中调用任意 BPF 辅助函数,需要引入 libbpf 库中提供这些函数定义的头文件。
在撰写本书时,eBPF 项目的常见做法是将 libbpf 作为子模块引入,并基于源码进行编译和安装。
若你将其作为子模块引入,只需进入 libbpf/src 目录,执行 make install 命令即可完成操作。
Application-speciic headers:
在项目中专门编写一个应用专属头文件,用于定义同时被程序用户态部分和eBPF 部分使用的所有结构体,是一种十分常见的做法。
hello-buffer-config.h 头文件定义了 data_t 结构体,通过这个结构体将事件数据从 eBPF 程序传递至用户态。
5.5.2 Deining Maps
引入头文件后,hello-buffer-config.bpf.c 源码中接下来的几行代码定义了用于映射(map)的结构体,具体如下:
1 | struct { |
在 BCC 中,这个名为 config 的映射是通过以下宏定义创建的:
1 | BPF_HASH(config, u64, struct user_msg_t); |
__uint, __type, __array 定义在头文件 bpf_helpers.h 中定义:
1 |
这些宏在基于 libbpf 的程序中通常遵循惯例使用,而且它们能让 map 定义的可读性稍好一些。
5.5.3 eBPF Program Sections
使用 libbpf 时,要求每个 eBPF 程序都需通过 SEC() 宏进行标记,该宏会定义程序的类型,示例如下:
1 | SEC("kprobe") |
这会在编译生成的 ELF 目标文件中创建一个名为 kprobe 的段,如此一来 libbpf 便知晓要将其加载为 BPF_PROG_TYPE_KPROBE 类型的 eBPF 程序。
根据程序类型的不同,可以通过段名称来指定程序要挂载的事件。libbpf 库会利用这一信息自动完成挂载配置,而非要求你在用户态代码中显式地手动完成这项操作。例如,若要在基于 ARM 架构的机器上自动挂载到 execve 系统调用对应的 kprobe 上,可以像这样指定段名称:
1 | SEC("kprobe/__arm64_sys_execve") |
这就要求你必须知晓该架构下系统调用对应的函数名。(也可以自行查找获取,比如查看目标机器上的 /proc/kallsyms 文件 —— 这个文件会列出内核的所有符号信息,其中就包含函数名)
libbpf 还能通过 k(ret)syscall 段名称进一步简化操作 —— 该段名称会告知加载器,自动将程序挂载到与架构相关的函数对应的 kprobe 上。
- libbpf 文档 中列举了有效的 section 名称和格式
1 | SEC("ksyscall/execve") |
BPF_KPROBE_SYSCALL是在libbpf中定义的宏,通过这个宏可以按名称便捷地访问系统调用的参数。eBPF 程序的名称为
hello,execve()的第一个参数为要执行的程序的路径名
在 BCC 版本的代码中,将消息字符串定义为 hello() 函数内的局部变量。这是因为 BCC(至少在撰写本文时)不支持全局变量。而在当前这个版本里,将它定义成了全局变量。
1 | char message[12] = "Hello World"; |
在 chapter4/hello-buffer-config.py 中 hello() 函数的定义如下:
1 | int hello(void *ctx) |
BPF_KPROBE_SYSCALL 宏是由 libbpf 提供的便利功能之一。你并非必须使用这个宏,但它能大幅简化开发流程。该宏会自动处理所有繁琐的底层工作,为传递给系统调用的所有参数提供按名访问的能力。在本示例中,它提供了一个 pathname 参数,这个参数指向一个字符串,该字符串存储了即将运行的可执行文件的路径 —— 而这正是 execve() 系统调用的第一个参数。
在 hello-buffer-config.bpf.c 中你会发现,ctx 变量并没有被显式定义,但是却在向 output perf 缓冲区提交数据时使用:
1 | bpf_perf_event_output(ctx, &output, BPF_F_CURRENT_CPU, &data, sizeof(data)); |
ctx 变量确实是存在的,它隐藏在 libbpf 库的头文件 bpf/bpf_tracing.h 中定义的 BPF_KPROBE_SYSCALL 宏里。
5.5.4 Memory Access with CO-RE
用于跟踪的 eBPF 程序对内存的访问受到限制,需要通过 bpf_probe_read_*() 系列的 BPF 辅助函数来实现。(此外还有一个 bpf_probe_write_user() 辅助函数,但它仅适用于实验场景)。在下一章将会看到,eBPF 验证器通常不允许你像在标准 C 语言中那样,直接通过指针读取内存(例如 x = p->y 这种写法)。
libbpf 库为 bpf_probe_read_*() 系列辅助函数提供了 CO-RE 封装,借助 BTF 信息的优势,让内存访问调用可以在不同内核版本间实现可移植。下面是 bpf_core_read.h 中定义的一个封装器的示例:
1 |
__builtin_preserve_access_index 会指示 Clang 在生成访问该内存地址的 eBPF 指令时,一并生成一个 CO-RE 重定位项。
正如你将在本章后续内容中看到的,CO-RE 重定位项 (relocation entry) 会指示 libbpf 在将 eBPF 程序加载至内核的过程中重写内存地址,以此适配不同内核间的 BTF 差异。如果 src 字段在其所属结构体中的偏移量,在目标内核上存在不同,重写后的指令也会将这一情况纳入考量。
libbpf 库提供了一个 BPF_CORE_READ() 宏,你可以通过它在单行代码中完成多次 bpf_core_read() 调用,而无需为每次指针解引用操作都单独调用一次辅助函数。例如,对于 d = a->b->c->d, 你可以通过下列代码实现:
1 | struct b_t *b; |
但可以使用更加紧凑的写法:
1 | d = BPF_CORE_READ(a, b, c, d); |
相关阅读:
5.5.5 License Deinition
正如在第 3 章中已经了解到的,eBPF 程序必须声明其许可证。
1 | char LICENSE[] SEC("license") = "Dual BSD/GPL"; |
5.6 Compiling eBPF Programs for CO-RE
5.6.1 Debug Information
你必须向 Clang 传入 -g 编译选项,让它生成调试信息 —— 这是 BTF 所必需的。
不过,-g 选项同时也会在输出的目标文件中添加 DWARF 调试信息,而这部分信息对 eBPF 程序来说并非必需。因此,可以执行以下命令剥离该部分内容,以减小目标文件的体积:
1 | llvm-strip -g <object file> |
5.6.2 Optimization
Clang 必须启用 -O2 优化选项(或更高优化级别),才能生成可通过验证器校验的 BPF 字节码。这一要求的必要性体现在一个典型场景中:默认情况下,Clang 会生成 callx <register> 指令来调用辅助函数,但 eBPF 并不支持通过寄存器寻址的方式完成函数调用。
5.6.3 Target Architecture
如果你要使用 libbpf 定义的某些宏,就需要在编译时指定目标架构。
libbpf 的头文件 bpf/bpf_tracing.h 中定义了多个平台相关的宏,比如本示例中用到的 BPF_KPROBE 和 BPF_KPROBE_SYSCALL。其中,BPF_KPROBE 宏可用于挂载到 kprobe 上的 eBPF 程序,而 BPF_KPROBE_SYSCALL 则是专门针对系统调用 kprobe 的变体宏。
kprobe 的入参是一个 pt_regs 结构体,该结构体存储了一份 CPU 寄存器内容的副本。由于寄存器具有架构相关性,pt_regs 结构体的定义也取决于程序运行所在的架构。这意味着,如果你想要使用这些宏,就必须告知编译器目标架构的具体类型。
你可以通过设置编译选项 -D __TARGET_ARCH_($ARCH) 来实现这一点,其中 $ARCH 代表具体的架构名称,例如 arm64、amd64 等。
5.6.4 Makeile
以下是用于编译 CO-RE 目标的示例 Makefile 指令:
1 | %.bpf.o: %.bpf.c vmlinux.h |
5.6.5 BTF Information in the Object File
内核中关于 BTF 的文档描述了 BTF 数据在 ELF 目标文件中的编码方式,其对应两个段:.BTF 段存储数据与字符串信息,.BTF.ext 段则包含函数与行号信息。
1 | $ readelf -S hello-buffer-config.bpf.o | grep BTF |
bpftool 工具可用于查看目标文件中的 BTF 数据,用法如下:
1 | bpftool btf dump file hello-buffer-config.bpf.o |
5.7 BPF Relocations
libbpf 库使 eBPF 程序适应其运行的目标内核上的数据结构体布局,即使该布局与编译代码的内核不同。为此,libbpf 需要 Clang 在编译过程中生成的 BPF CO-RE 重定位信息。
可以通过 linux/bpf.h 头文件中 struct bpf_core_relo 的定义了解有关重定位如何工作的更多信息:
1 | struct bpf_core_relo { |
eBPF 程序的 CO-RE 重定位数据,会为每条需要重定位的指令配备一个此类结构体。
假设某条指令要将一个寄存器的值设置为某个结构体中某个字段的值,那么该指令对应的 bpf_core_relo 结构体(通过 insn_off 字段来标识)会对该结构体的 BTF 类型(type_id 字段)进行编码,同时还会指明该字段相对于此结构体的访问方式(access_str_off 字段)。
内核数据结构的重定位数据会由 Clang 自动生成,并编码到 ELF 目标文件中。正是在 vmlinux.h 文件开头附近找到的下一行代码,促使 Clang 执行了这一操作:
1 |
preserve_access_index: 指示 Clang 为类型定义生成 BPF CO-RE 重定位信息。clang attribute push: 将应用于所有后续的类型定义,直至文件末尾出现clang attribute pop为止。这意味着 Clang 会为vmlinux.h中定义的所有类型都生成对应的重定位信息。
当加载 BPF 程序时,可通过 bpftool 工具并添加 -d 参数开启调试信息,来查看重定位操作的执行过程。
1 | bpftool -d prog load hello.bpf.o /sys/fs/bpf/hello |
会看到类似下面的输出信息:
1 | libbpf: CO-RE relocating [22] struct pt_regs: found target candidate [134] struct pt_regs in [vmlinux] |
5.8 CO-RE User Space Code
在许多应用场景中,你不会希望要求用户通过运行 bpftool 工具来加载 eBPF 程序。相反,更希望将该功能集成到一个专用的用户态程序中,并将其编译为可执行文件提供给用户。
不同编程语言中都存在若干支持 CO-RE 技术的框架,它们的实现原理是在将 eBPF 程序加载至内核时完成重定位操作。
本章将演示基于 libbpf 库的 C 语言实现代码;除此之外,其他可选方案还包括 Go 语言的 cilium/ebpf 和 libbpfgo 包,以及适用于 Rust 语言的 Aya 框架。关于这些方案的更多内容,会在第 10 章展开详细探讨。
5.9 The Libbpf Library for User Space
libbpf 库提供了一系列函数,这些函数对第 4 章中讲到的 bpf() 系统调用及其相关系统调用进行了封装,可用于执行各类操作,例如将程序加载至内核并挂载到事件上,或是从用户态访问映射的相关信息。使用这些抽象功能的标准且最简便的方法,是借助自动生成的 BPF 骨架代码 (BPF skeleton code)。
5.9.1 BPF Skeletons
使用 bpftool 从现有的 ELF 文件格式的 eBPF 对象中自动生成框架代码:
1 | bpftool gen skeleton hello-buffer-config.bpf.o > hello-buffer-config.skel.h |
查看这个骨架头文件你会发现,它包含了 eBPF 程序与映射的结构体定义,同时还包含若干名称均以 hello_buffer_config_bpf__ 开头的函数(该前缀基于目标文件的名称生成)。这些函数负责管理 eBPF 程序与映射的生命周期。
在生成的骨架文件末尾,你会看到一个名为 hello_buffer_config_bpf__elf_bytes 的函数,该函数会返回 ELF 目标文件 hello-buffer-config.bpf.o 的字节内容。骨架文件生成完成后,我们实际上就不再需要这个目标文件了。你可以通过以下步骤验证这一点:先运行 make 命令生成 hello-buffer-config 可执行文件,然后删除上述 .o 文件 —— 此时可执行文件本身已包含所需的 eBPF 字节码。
示例:[hello-bufer-config.c]
Loading programs and maps into the kernel
1 | skel = hello_buffer_config_bpf__open_and_load(); |
顾名思义,该函数包含两个阶段:打开与加载。
“打开” 阶段负责读取 ELF 数据,并将其各个段转换为用于表示 eBPF 程序和映射的结构体。
“加载” 阶段则会将这些映射和程序加载至内核,并根据需要执行各类 CO-RE 修正操作。
这两个阶段可以很方便地分开处理,因为骨架代码提供了独立的 name__open() 和 name__load() 函数。这让你能够在加载 eBPF 程序之前,对相关信息进行操作。这种做法常用于在加载程序前完成配置工作。例如,我可以像这样将一个全局计数器变量 c 初始化为某个值:
1 | skel = hello_buffer_config_bpf__open(); |
hello_buffer_config_bpf__open() 函数与 hello_buffer_config_bpf__load() 函数的返回数据类型,均为一个名为 hello_buffer_config_bpf 的结构体。该结构体定义在骨架头文件中,包含了目标文件内所有映射、程序以及数据的相关信息。
Accessing existing maps
bpftool遍历所有的映射,查找与指定名称相匹配的那一个。- 在两个不同的 eBPF 程序之间使用映射 (map) 共享信息。
bpf_map__set_autocreate() 函数允许覆盖 libbpf 的自动创建(映射)行为。
映射(map)支持被固定(pin),如果已知其固定路径,就可以通过 bpf_obj_get() 函数获取一个指向已有映射的文件描述符。
示例:[find-map.c]
1 | struct bpf_map_info info = {}; |
- 使用 bpftool 创建 map:
1 | bpftool map create /sys/fs/bpf/findme type array key 4 value 32 entries 4 name findme |
- 运行 find-map
1 | $ ./find-map |
Attaching to events
本示例中的下一个骨架函数会将该程序挂载到 execve 系统调用函数上:
1 | err = hello_buffer_config_bpf__attach(skel); |
libbpf 库会自动从该程序的 SEC() 定义中提取挂载点信息。如果未完整定义挂载点,libbpf 还提供了一系列专用函数,例如 bpf_program__attach_kprobe、bpf_program__attach_xdp 等,用于挂载不同类型的 eBPF 程序。
Managing an event bufer
性能缓冲区的配置需调用 libbpf 库自身定义的函数,而非骨架代码中定义的函数。
1 | pb = perf_buffer__new(bpf_map__fd(skel->maps.output), 8, handle_event, lost_event, NULL, NULL); |
perf_buffer__new()函数将 “output” 映射的文件描述符作为第一个参数。参数
handle_event是一个回调函数,当有新数据写入性能缓冲区时,该函数会被调用如果性能缓冲区空间不足,导致内核无法写入数据条目时,
lost_event函数则会被触发执行。
最后,程序必须对性能缓冲区进行持续轮询:
1 | while (true) { |
参数 100 代表超时时间,单位为毫秒。当有数据写入或缓冲区被写满时,此前设置好的回调函数便会相应触发执行。
清理阶段,会释放性能缓冲区,并销毁内核中的 eBPF 程序与映射,具体操作如下:
1 | perf_buffer__free(pb); |
libbpf 库中提供了一整套与 perf_buffer_* 和 ring_buffer_* 相关的函数,用于帮助开发者管理事件缓冲区。
5.9.2 Libbpf Code Examples
有大量基于 libbpf 的优质 eBPF 程序示例可供参考,你可以将其作为灵感来源和指导,用于编写自己的程序。
libbpf-bootstrap: 帮你快速上手一系列示例程序。
libbpf-tools directory: BCC 项目已将许多原本基于 BCC 框架的工具,迁移至
libbpf版本。
5.10 Summary
BTF 数据中
type_id 0表示是 void 类型。vmlinux.h文件派生自内核源码头文件,但它并未包含这些头文件中通过#define定义的常量值。BPF Skeletons