目前在 uapi/linux/bpf.h 中大约定义了 30 种程序类型 (program types),以及 40 多种挂载点类型 (attachment types)。
7.1 Program Context Arguments
所有 eBPF 程序都接收一个指针类型的上下文参数,但该指针指向的具体结构取决于触发它的事件类型。eBPF 程序员需要编写能够接收相应上下文类型的程序;例如,如果事件是一个跟踪点(tracepoint),那么假装上下文参数指向一个网络包是毫无意义的。
定义不同类型的程序可以让验证器(verifier)确保上下文信息被正确处理,并强制实施关于哪些辅助函数(helper functions)是允许调用的规则。
延伸阅读:
7.2 Helper Functions and Return Codes
验证器会检查程序所使用的所有辅助函数是否与其程序类型兼容。上一章的示例表明,bpf_get_current_pid_tgid() 辅助函数在 XDP 程序中是不被允许的。
程序类型还决定了程序返回码(return code)的含义。同样以 XDP 为例,返回码的值会告诉内核,在 eBPF 程序完成处理后,该如何处理这个数据包 —— 这可能包括将其传递给网络协议栈、丢弃它,或者将其重定向到另一个网络接口。
获取当前内核版本中每种程序类型可用的辅助函数列表:
1 | bpftool feature |
辅助函数(Helper functions)被视为 UAPI(Linux 内核外部稳定接口)的一部分。因此,一旦某个辅助函数在内核中被定义,即便内核的内部函数和数据结构可能会发生变化,该辅助函数在未来也不应改变。
7.3 Kfuncs
尽管内核版本之间存在变更的风险,但 eBPF 程序员仍希望能够从 eBPF 程序中访问某些内部函数。这可以通过一种称为 BPF 内核函数(kfuncs) 的机制来实现。
Kfuncs 允许将内核内部函数注册到 BPF 子系统,以便验证器允许从 eBPF 程序中调用它们。对于每个被允许调用某个给定 kfunc 的 eBPF 程序类型,都有一个对应的注册项。
与辅助函数不同,kfuncs 不提供兼容性保证,因此 eBPF 程序员必须考虑内核版本之间发生变化的可能性。
eBPF 程序的类型决定了它可以挂载到哪些事件上,这反过来又定义了它接收的上下文信息的类型。程序类型还定义了它可以调用的辅助函数和 kfuncs 的集合。
7.4 Tracing
程序类型大致被分为两类:跟踪(或 perf)程序类型和网络相关程序类型。
附加到 kprobes、tracepoints、raw tracepoints、fentry/fexit probes 和 perf events 的程序,都是为了内核中的 eBPF 程序能够高效的将跟踪信息传递到用户空间中。
- 查看附加到 perf 相关事件的程序:
1 | $ cd learning-ebpf/chapter7 |
挂载到
execve()系统调用入口点的 kprobe挂载到内核函数
do_execve()的 kprobe放置在
execve()系统调用入口处的 tracepoint。在
execve()处理过程中被调用的原始 tracepoint(raw tracepoint)的两个版本。其中一个,正如你将在本节中看到的,是启用了 BTF 的版本。
7.4.1 Kprobes and Kretprobes
几乎可以将 kprobe 程序附加到内核的任何位置。
通常情况下,使用 kprobes 附加到函数的入口,使用 kretprobes 附加到函数的出口,但也可以使用 kprobes 附加到函数入口后的某个指定偏移量。
如果某个函数恰好被内联(inlined)了,那么就不会有可供你的 eBPF 程序挂载的 kprobe 入口点。
- offset 0
1 | $ bpftool perf list |
Attaching kprobes to syscall entry points
- 附加到系统调用
execve()的 kprobe
1 | SEC("ksyscall/execve") |
挂载到系统调用(syscalls)的一个原因是,它们是稳定的接口,在内核版本之间不会发生变化。
然而,出于将在第 9 章详细介绍的原因,安全工具不应依赖基于系统调用的 kprobe。
Attaching kprobes to other kernel functions
- kprobes 也可以附加到内核中的任何非内联函数
1 | SEC("kprobe/do_execve") |
注:在 Linux 5.x 及以上的版本使用如下代码
1 | SEC("kprobe/do_execveat_common.isra.0") |
由于 do_execve() 不是系统调用,该示例与之前的示例有以下几点不同:
SEC名称的格式与之前挂载到系统调用入口点的版本完全相同,但无需定义特定于平台的变体,因为do_execve()与大多数内核函数一样,是所有平台通用的。使用了
BPF_KPROBE宏,而不是BPF_KPROBE_SYSCALL。两者的意图完全相同,只是后者会处理系统调用参数。还有一个重要区别:系统调用的
pathname参数是一个指向字符串的指针(char *),但对于这个函数,参数名为filename,它是一个指向struct filename的指针,这是内核内部使用的一种数据结构。
filename 是根据内核中 do_execve 的函数原型确定。由于参数在内存中按顺序排列,可以忽略最后 n 个参数,但如果想使用后面的参数,则不能忽略列表中靠前的参数。
1 | int do_execve(struct filename *filename, |
filename->name 指向即将运行的可执行文件的名称。在示例代码中使用以下行获取该名称:
1 | const char *name = BPF_CORE_READ(filename, name); |
系统调用 kprobe 的上下文参数是一个结构体,它代表了用户空间传递给该系统调用的值。而 “普通”(非系统调用)kprobe 的上下文参数则是一个结构体,它代表了调用该函数的内核代码传递给它的参数,因此这个结构体取决于被调用函数的定义。
Kretprobes 与 kprobes 非常相似,不同之处在于它们在函数返回时触发,并且可以访问返回值而不是参数。
7.4.2 Fentry/Fexit
从内核版本 5.5 开始(适用于 x86 处理器;BPF tramopline 支持在 Linux 6.0 之前不适用于 ARM 处理器),引入了一种更高效的机制来跟踪进入和退出内核函数的方式以及 BPF trampoline 的概念。
fentry/fexit 现在是首选的跟踪进入或退出内核函数的方法。
1 | SEC("fentry/do_execve") |
fentry 和 fexit 的附加点设计得比 kprobes 更高效,且 fexit hook 可以访问函数的输入参数,而 kretprobe 不能。
在 libbpf-bootstrap 的示例中 可以看到两个等效的示例:
1 | SEC("kretprobe/do_unlinkat") |
1 | SEC("fexit/do_unlinkat") |
7.4.3 Tracepoints
Tracepoints 是内核开发者预先在代码中设置的、可用于触发事件记录的特定位置,在不同内核版本之间具有稳定性。
- 查看内核上可用的跟踪子系统集合:
1 | cat /sys/kernel/tracing/available_events |
如下所示,当内核开始处理系统调用 ececve() 时,tracepoint syscalls:sys_enter_execve 会被触发。
1 | SEC("tp/syscalls/sys_enter_execve") |
BTF 可以帮助我们处理 tracepoint 的上下文(context)。
但是在 BTF 不可用的情况下,以下是一些应对措施:每个 tracepoint 都有一个格式(format),用来描述从跟踪点中被追踪输出的字段(fields)。
以下是 execve() 系统调用入口处跟踪点的格式说明:
1 | cat /sys/kernel/tracing/events/syscalls/sys_enter_execve/format |
1 | name: sys_enter_execve |
可以使用上述信息定义一个名为 my_syscalls_enter_execve 的结构体:
eBPF 程序不允许访问前四个字段。
1 | struct my_syscalls_enter_execve { |
附加到该跟踪点的 eBPF 示例程序,可以将指向此类型的指针用作其上下文(context)参数,然后就可以访问这个结构体的内容了。
1 | int tp_sys_enter_execve(struct my_syscalls_enter_execve *ctx) { |
当使用跟踪点(tracepoint)程序类型时,传递给 eBPF 程序的结构体已由一组原始参数映射而来。
为获得更优性能,可以通过原始跟踪点(raw tracepoint)eBPF 程序类型直接访问这些原始参数。此时,段定义(section definition)应以 raw_tp(或 raw_tracepoint)开头,而非 tp。
1 | SEC("raw_tp/sched_process_exec") |
7.4.4 BTF-Enabled Tracepoints
在 BTF 支持下,在 vmlinux.h 中会定义一个与传递给跟踪点 eBPF 程序的上下文结构体相匹配的结构体。
eBPF 程序应该使用 SEC("tp_btf/tracepoint name"),其中跟踪点名称是 /sys/kernel/tracing/available_events 中列出的可用事件之一。
1 | SEC("tp_btf/sched_process_exec") |
结构名称与跟踪点名称匹配,前缀为 trace_event_raw_ 。
7.4.5 User Space Attachments
uprobes 和 uretprobes 用于挂载到用户态函数的入口和出口。用户态静态定义跟踪点 user statically defined tracepoints (USDTs) 用于挂载应用程序代码或用户态库中指定的跟踪点。这些都是用 BPF_PROG_TYPE_KPROBE 类型。
如果你正在使用 libbpf,那么 SEC() 宏可用于为这些用户态探测程序 (user space probes) 定义自动挂载点。具体格式可参考 Program Types and ELF Sections。
比如,将用户态入口探测(uprobe)挂载到 OpenSSL 中 SSL_write() 函数的起始处:
1 | SEC("uprobe/usr/lib/aarch64-linux-gnu/libssl.so.3/SSL_write") |
一些例子:
7.4.6 LSM
BPF_PROG_TYPE_LSM 程序附加到 Linux 安全模块 (LSM) API,这是内核中的一个稳定接口,最初供内核模块用来强制执行安全策略。
BPF_PROG_TYPE_LSM 程序使用 bpf(BPF_RAW_TRACEPOINT_OPEN) 附加,并且在许多方面它们被视为跟踪程序。
BPF_PROG_TYPE_LSM 程序的一个有趣特征是返回值会影响内核的行为方式。非零返回值表示安全检查未通过,因此内核不会继续执行要求完成的任何操作。这与忽略返回值的 perf 相关程序类型有显着差异。
7.5 Networking
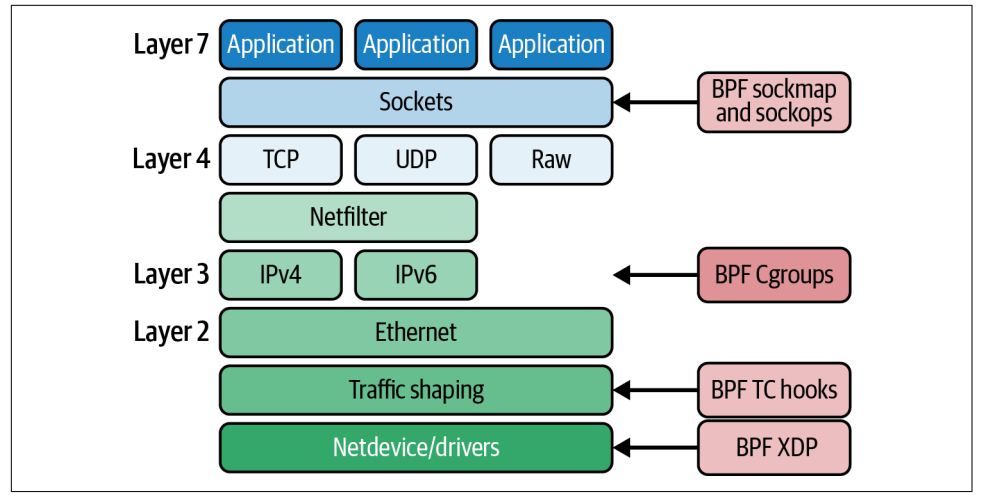
这些程序类型都需要具备 CAP_NET_ADMIN 和 CAP_BPF 能力(capabilities),或者具备 CAP_SYS_ADMIN 能力,才能被允许加载和运行。
传递给这些类型程序的上下文是相关的网络消息,不过具体的结构体类型取决于内核在网络协议栈中相应位置所拥有的数据形式。
在协议栈的底层,数据以第二层(Layer 2)网络包的形式存在,本质上就是一串已经或即将在 “线路上 (on the wire)” 传输的字节;而在协议栈的顶层,应用程序使用套接字(sockets),内核则创建套接字缓冲区(socket buffers)来处理通过这些套接字发送和接收的数据。
第 7 层涵盖供应用程序使用的格式,例如 HTTP、DNS 或 gRPC;TCP 位于第 4 层;IP 位于第 3 层;而以太网(Ethernet)和 WiFi 位于第 2 层。网络协议栈的作用之一,就是在这些不同格式之间转换消息。
7.5.1 Sockets
BPF_PROG_TYPE_SOCKET_FILTER是最早被添加到内核中的程序类型。它的作用是过滤一份套接字数据的副本,这份副本可以被发送给像tcpdump这样的可观测性工具。套接字是特定于第 4 层(TCP)连接的。
BPF_PROG_TYPE_SOCK_OPS允许 eBPF 程序拦截发生在套接字上的各种操作和动作,并为该套接字设置诸如 TCP 超时值之类的参数。套接字只存在于连接的端点,而不存在于它们可能经过的任何中间设备(middleboxes)上。BPF_PROG_TYPE_SK_SKB程序通常与一种特殊的映射(map)类型结合使用,这种映射中保存着一组对套接字的引用,从而提供所谓的 sockmap 操作:即在套接字层将流量重定向到不同的目的地。
7.5.2 Traffic Control (TC)
Linux 内核中有一个完整的子系统与 TC(流量控制)相关,如果你快速浏览一下 tc 命令的手册页,就会对它的复杂性,以及在网络数据包处理方式上提供深层次的灵活性和可配置性对于通用计算的重要性有一个直观的认识。
可以挂载 eBPF 程序,为入口 (ingress) 和出口 (egress) 流量的网络数据包提供自定义的过滤器和分类器。这是 Cilium 项目的基础组件之一,在下一章会给出一些示例。
如果你迫不及待想了解,Quentin Monnet 的博客上也有一些很好的例子。这种操作既可以通过编程方式完成,也可以选择使用 tc 命令来管理这类 eBPF 程序。
7.5.3 XDP
XDP (eXpress Data Path)
在第 3 章中使用以下命令加载了 eBPF 程序并将其挂载到了 eth0 接口上:
1 | bpftool prog load hello.bpf.o /sys/fs/bpf/hello |
XDP 程序是另一种可以使用 Linux 网络工具进行管理的程序示例 —— 在这种情况下,使用的是 iproute2 中 ip 命令的 link 子命令。将该程序加载并挂载到 eth0 接口上的大致等效命令如下:
1 | ip link set dev eth0 xdp obj hello.bpf.o sec xdp |
这条命令从 hello.bpf.o 对象文件中读取标记为 xdp 节的 eBPF 程序,并将其挂载到 eth0 网络接口上。
现在,针对该接口执行 ip link show 命令时,会包含一些关于已挂载 XDP 程序的信息:
1 | 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 xdpgeneric qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000 |
可以使用 ip link 命令像这样移除 XDP 程序:
1 | ip link set dev eth0 xdp off |
7.5.4 Flow Dissector
流解析器(flow dissector)在网络协议栈的各个点被用来从数据包头部提取细节。类型为 BPF_PROG_TYPE_FLOW_DISSECTOR 的 eBPF 程序可以实现自定义的数据包解析。
相关阅读:
7.5.5 Lightweight Tunnels
BPF_PROG_TYPE_LWT_* 系列程序类型可用于在 eBPF 程序中实现网络封装。这些程序类型也可以通过 ip 命令进行管理,但这次涉及的是 route 子命令。在实际应用中,它们的使用频率并不高。
7.5.6 Cgroups (control groups)
eBPF 程序可以挂载到 cgroup(即 “control group” 的缩写)上。Cgroup 是 Linux 内核中的一个概念,用来限制某个进程或某组进程能够访问的资源集合。
Cgroup 是实现容器(或 Kubernetes Pod)之间隔离的机制之一。将 eBPF 程序挂载到 cgroup 上,可以实现只对该 cgroup 中的进程生效的自定义行为。所有进程都与某个 cgroup 相关联,包括那些没有在容器中运行的进程。
有几种与 cgroup 相关的程序类型,而且可以挂载它们的钩子(hook)甚至更多。至少在撰写本文时,它们几乎都与网络相关,不过也有一种 BPF_CGROUP_SYSCTL 程序类型,可以挂载到影响特定 cgroup 的 sysctl 命令上。
例如,有几种特定于 cgroup 的与套接字相关的程序类型: BPF_PROG_TYPE_CGROUP_SOCK 和 BPF_PROG_TYPE_CGROUP_SKB 。eBPF 程序可以决定某个给定的 cgroup 是否被允许执行请求的套接字操作或数据传输。这对于网络安全策略的实施非常有用(我将在下一章中介绍)。套接字程序还可以 “欺骗” 调用进程,让它以为自己正在连接到某个特定的目标地址。
7.5.7 Infrared Controllers
BPF_PROG_TYPE_LIRC_MODE2 类型的程序可以挂载到红外控制器设备的文件描述符上,用于提供红外协议的解码功能。在撰写本文时,这种程序类型需要 CAP_NET_ADMIN 能力,但我认为这恰恰说明了,将程序类型简单划分为 “跟踪相关” 和 “网络相关” 并不能完全涵盖 eBPF 所能解决的各种应用场景。
7.6 BPF Attachment Types
挂载类型(attachment type) 提供了对程序可以挂载到系统中何处的更细粒度控制。对于某些程序类型,它们与可以挂载的钩子(hook)类型之间存在一一对应的关系,因此挂载类型由程序类型隐式定义。例如,XDP 程序挂载到网络协议栈中的 XDP 钩子上。而对于少数程序类型,则必须显式指定挂载类型。
挂载类型会参与决定哪些辅助函数是合法的,并且在某些情况下还会限制对部分上下文信息的访问。
你也可以在内核函数 bpf_prog_load_check_attach(定义在 bpf/syscall.c 中)中看到哪些程序类型需要指定挂载类型,以及哪些挂载类型是合法的。
例如,以下是针对 CGROUP_SOCK 类型程序检查挂载类型的代码:
1 | case BPF_PROG_TYPE_CGROUP_SOCK: |
这种程序类型可以挂载在多个位置:在套接字创建时、在套接字释放时,或者在 IPv4 或 IPv6 中完成绑定(bind)之后。
相关阅读:
7.7 Summary
在本章中,你了解到各种 eBPF 程序类型可用于挂载到内核中的不同钩子点。如果你想编写响应特定事件的代码,就需要确定适合挂载该事件的程序类型。传入程序的上下文取决于程序类型,并且内核对程序返回码的处理方式也可能因程序类型而异。