eBPF 允许开发者构建满足特定需求的网络功能,而无需将这些功能强制推行给所有上游内核用户。
基于 eBPF 的网络工具现在被广泛使用,并已被证明在大规模应用中非常有效。
- Cilium
- 自 2017 年以来,所有进出 Facebook 的数据包都经过了 XDP 程序的处理
- Cloudflare 使用 eBPF 来进行 DDoS(分布式拒绝服务)保护
8.1 Packet Drops
有几种涉及丢弃特定传入数据包和允许其他数据包的网络安全功能。
- 防火墙
- 根据源、目的 IP 地址以及端口号,逐个数据包决定是否允许数据包。
- DDoS 防护
- 可能要跟踪来自特定来源的数据包的到达速度,检测数据包内容的某些特征,以确定攻击者或一组攻击者正试图用流量淹没接口。
- 致命数据包漏洞 (packet-of-death vulnerabilities)
- 传统上,当发现这种内核漏洞时,需要安装修复的新内核,这需要停机维护。
- 能检测并丢弃这些恶意数据包的 eBPF 程序可以动态安装,在不影响机器上运行的任何应用程序的情况下立即保护主机。
8.1.1 XDP Program Return Codes
网络数据包的到达会触发 XDP 程序。程序会检查数据包,检查完毕后,返回值会给出一个决策(verdict),指出下一步该如何处理该数据包:
- XDP_PASS
- 数据包应以正常方式发送到网络协议栈(就像没有 XDP 程序时的执行流程)
- XDP_DROP
- 立即丢弃数据包
- XDP_TX
- 将数据包从其到达的同一接口发送回去
- XDP_REDIRECT
- 将数据包从不同的网络接口发送回去
- XDP_ABORTED
- 丢弃数据包,但它的使用意味着出现错误或出现意外情况,而不是 “正常” 决定丢弃数据包
决定是否丢弃数据包的 XDP 程序大致如下:
1 | SEC("xdp") |
每当一个入站网络数据包到达其所连接的接口时,XDP 程序就会被触发。ctx 参数是一个指向 xdp_md 结构体的指针,该结构体保存了传入数据包的元数据。
8.1.2 XDP Packet Parsing
xdp_md 结构体的定义如下:
1 | struct xdp_md { |
不要被前三个字段的 __u32 类型所迷惑,因为它们实际上是指针。
data 字段指示数据包在内存中的起始位置,data_end 表示数据包的结束位置。
数据包前面的内存中还有一个区域,位于 data_meta 和 data 之间,用于存储有关该数据包的元数据。该区域可用于协调多个 eBPF 程序,这些程序可能会在数据包通过网络协议栈的不同位置处理同一个数据包。
hello ping
示例代码中有一个名为 ping() 的 XDP 程序,每当检测到 ping (ICMP) 数据包时,它就会简单地生成一行跟踪信息。该程序的代码如下:
1 | SEC("xdp") |
运行方式如下:
1 | $ cd learning-ebpf/chapter8 |
1 | $ ping localhost |
1 | $ cat /sys/kernel/tracing/trace_pipe |
每秒有两行跟踪信息,是因为回环接口同时接收 ping 请求和 ping 响应。
通过添加如下代码,在协议匹配时返回 XDP_DROP,可以实现丢弃 ping 数据包:
1 | if (protocol == 1) // ICMP |
在这个 XDP 程序中,大部分工作都是在一个名为 lookup_protocol() 的函数中完成的,该函数用于确定第 4 层协议类型。这只是一个示例,并不是解析网络数据包的高质量实现!
接收到的网络数据包由一串字节组成,其布局如图所示:
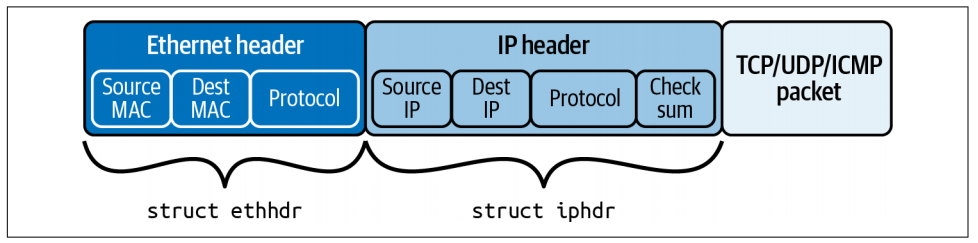
ethhdr 和 iphdr 的定义如下:
1 | struct ethhdr { |
lookup_protocol() 函数接收 ctx 结构体作为参数,该结构体保存数据包在内存中的位置信息,并返回它在 IP 报头中找到的协议类型。代码如下:
1 | // Returns the protocol byte for an IP packet, 0 for anything else |
bpf_ntohs() 函数可确保两个字节按照主机序排列。网络协议是大端字节序,但大多数处理器是小端字节序,这意味着它们以不同的顺序保存多字节值。此函数将从网络序转换为主机序(如有必要)。
当从长度超过一个字节的网络数据包中提取字段信息时,都应该使用 bpf_ntohs()。
8.2 Load Balancing and Forwarding
XDP 程序不仅限于检查数据包的内容,还可以修改数据包的内容。
如图所示,这是一组在同一主机上运行的容器。有一个客户端、一个负载均衡器和两个后端,每个后端都在自己的容器中运行。负载均衡器接收来自客户端的流量并将其转发到任意一个后端容器。
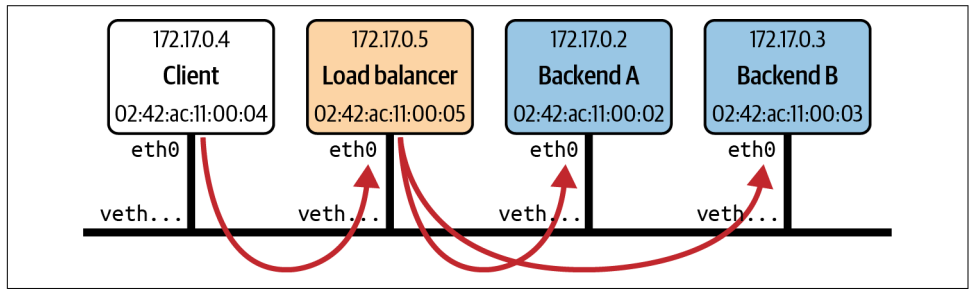
示例代码仅用于学习,请勿用于生产环境。
1 | SEC("xdp_lb") |
8.3 XDP Offloading
有一些网卡支持完整的 XDP 卸载 (XDP Offloading) 功能,它们确实可以在自己的处理器上运行 eBPF 程序来处理传入的数据包。
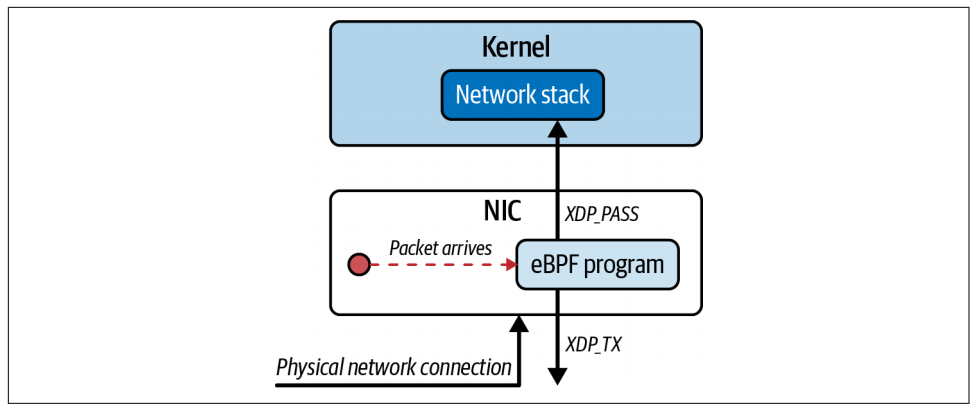
这就意味着,从同一物理接口丢弃或重定向回来的数据包(如本章前面的数据包丢弃和负载均衡示例),主机内核永远不会看到,主机上的 CPU 周期也不会用于处理这些数据包,因为所有工作都是在网卡上完成的。
即使物理网卡不支持完整的 XDP 卸载,许多 NIC 驱动程序也支持 XDP 钩子,这可以最大限度地减少 eBPF 程序处理数据包所需的内存复制。
8.4 Traic Control (TC)
当网络数据包到达这一附加点时,它将以 sk_buff 的形式存在于内核内存中,sk_buff 在整个内核的网络协议栈都有使用。
在 TC 子系统中附加的 eBPF 程序会接收一个指向 sk_buff 结构体的指针作为上下文参数。
您可能想为什么 XDP 程序不在其上下文中使用 sk_buff 结构。答案是,XDP 钩子发生在网络数据到达网络协议栈之前以及 sk_buff 结构体建立之前。
TC 子系统旨在调节网络流量的调度方式。例如,您可能希望限制每个应用程序的可用带宽,以便它们都能获得公平的机会。但在调度单个数据包时,带宽并不是一个非常有意义的术语,因为它是指发送或接收的平均数据量。某个特定的应用程序可能非常容易有突发流量,或者另一个应用程序可能对网络延迟非常敏感,因此 TC 可以对数据包的处理方式和优先级进行更精细的控制。
延伸阅读:
引入 eBPF 程序是为了对 TC 内使用的算法进行自定义控制。但由于 eBPF 程序具有操纵、丢弃或重定向数据包的功能,因此也可用作复杂网络行为的构建模块。
网络协议栈中给定的网络数据流有两个方向:入口(ingress,从网络接口进入)或出口(egress,向网络接口输出)。eBPF 程序可以附加在任一方向上,并只影响该方向上的流量。
与 XDP 不同, TC 可以附加多个 eBPF 程序,并按顺序进行处理。
传统的流量控制分为:
- 分类器 (classifers):根据某些规则对数据包进行分类
- 单独的操作 (separate actions):根据分类器的输出决定如何处理数据包。
可以有一系列分类器,它们都被定义为 qdisc 或排队规则(queuing discipline)的一部分。
eBPF 程序是作为分类器附加在程序上的,但它们也可以决定在同一程序中采取什么行动。该操作由程序的返回值(其值在 linux/pkt_cls.h 中定义)表示:
- TC_ACT_SHOT: 告诉内核丢弃数据包
- TC_ACT_UNSPEC: 就像 eBPF 程序尚未在此数据包上运行一样(因此它将被传递到序列中的下一个分类器(如果有))
- TC_ACT_OK: 告诉内核将数据包传递到网络协议栈的下一层
- TC_ACT_REDIRECT: 将数据包发送到不同网络设备的入口或出口路径
示例1:只是生成一行跟踪信息,然后告诉内核丢弃数据包:
1 | int tc_drop(struct __sk_buff *skb) { |
示例2:丢弃 ICMP (ping) 请求数据包
1 | int tc(struct __sk_buff *skb) { |
sk_buff 结构体具有指向数据包数据开始和结束的指针,这与 xdp_md 结构体非常相似,数据包的解析过程也大致相同。同样,要通过验证,必须明确检查对数据的任何访问是否在 data 和 data_end 之间的范围内。
既然 XDP 已经实现了同样的功能,为什么还要在 TC 层实现这样的功能呢?
- 可以使用 TC 程序处理出口流量,而 XDP 只能处理入口流量。
- 由于 XDP 会在数据包到达时立即触发,此时并不存在与数据包相关的
sk_buff内核数据结构。如果 eBPF 程序对内核为该数据包创建的sk_buff感兴趣或想对其进行操作,那么 TC 附加点是合适的。
延伸阅读:
示例3:识别收到的 ping 请求,并作出 ping 响应。
1 | int tc_pingpong(struct __sk_buff *skb) { |
如今,许多网络功能都是由用户空间服务处理的,但如果用 eBPF 程序来替代,很可能会大大提高性能。在内核中处理的数据包不需要通过协议栈的所有部分;数据包不需要传输到用户空间进行处理,而响应也不需要传回内核。更重要的是,两者可以并行运行——eBPF 程序可以为任何需要复杂处理而自己又无法处理的数据包返回 TC_ACT_OK,这样它就可以正常传递到用户空间服务。
8.5 Packet Encryption and Decryption
在很多情况下,应用程序会借助运行在用户态的 OpenSSL、BoringSSL 这类库来对数据进行加密。如果想要以明文形式追踪这些数据,可以编写一个 eBPF 程序,并将其挂载到用户态代码中合适的位置。
8.5.1 User Space SSL Libraries
使用 OpenSSL 的应用程序,通过调用 SSL_write() 函数来发送待加密的数据,并通过 SSL_read() 函数,获取网络上以加密形式传输、经解密后得到的明文数据。
使用用户态探针(uprobes)将 eBPF 程序挂载到这些函数上,就可以让程序在数据被加密之前,或是被解密之后,以明文形式监看任何使用该共享库的应用程序的数据。并且这一过程不需要任何密钥,因为密钥已经由应用程序自行提供。
Pixie 项目中有一个名为 openssl-tracer 的非常简单直观的示例,该示例的 eBPF 程序代码位于 openssl_tracer_bpf_funcs.c 文件中。下面是该代码里,使用性能缓冲区(perf buffer)将数据发送到用户态的部分。
1 | static int process_SSL_data(struct pt_regs* ctx, uint64_t id, enum ssl_data_event_type type, |
如果这些数据被发送到用户态,那么可以合理地推断,这些数据一定是未加密的明文格式。那么,这个数据缓冲区的内容是从哪里获取的呢?你可以通过查看 process_SSL_data() 函数的调用位置来找到答案。该函数有两处调用点:一处用于处理读取的数据,另一处用于处理写入的数据。图 8-4 展示了在读取本机收到的加密数据时,整个流程的执行情况。
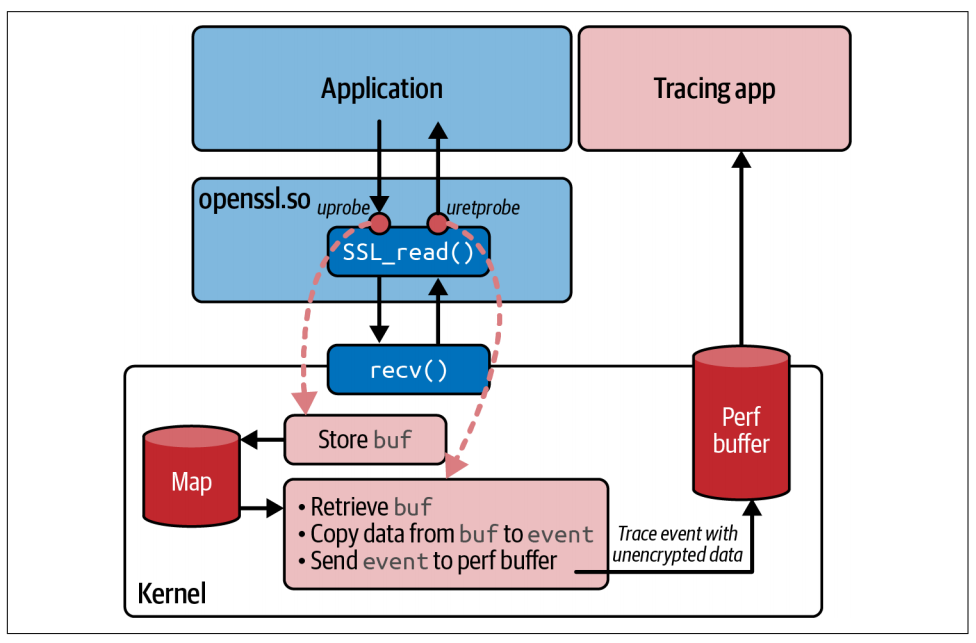
读取数据时,你向 SSL_read() 传入一个缓冲区指针,函数返回后,该缓冲区中就会存放解密后的明文数据。和 kprobe 非常相似,函数的入参(包括这个缓冲区指针),只有挂载在函数入口点的 uprobe 才能获取到,因为存储这些参数的寄存器,在函数执行过程中很可能会被覆盖。但缓冲区里的有效数据要等到函数退出时才会就绪,这时你就可以通过 uretprobe 来读取这些数据。
因此,这个示例遵循了 kprobe 和 uprobe 的一种通用模式,如图 8-4 所示:入口探针通过映射(map)临时存储输入参数,返回探针便可以从中读取这些参数。我们来看看实现这一逻辑的代码,首先从挂载在 SSL_read() 函数入口处的 eBPF 程序开始讲解。
1 | // Function signature being probed: |
这是对应的返回探针程序:
1 | int probe_ret_SSL_read(struct pt_regs* ctx) { |
BCC 项目包含一个名为 sslsniff 的工具,该工具同时支持 GnuTLS 和 NSS。
8.6 eBPF and Kubernetes Networking
在 Kubernetes 环境中,应用程序被部署在 Pod 里。每个 Pod 是由一个或多个容器组成的集合,这些容器共享内核命名空间(namespaces)和控制组(cgroups),从而实现 Pod 之间、以及 Pod 与其所在宿主机之间的相互隔离。
就本章内容而言,一个 Pod 通常拥有独立的网络命名空间和专属的 IP 地址。这意味着内核会为该命名空间维护一套独立的网络栈结构,与宿主机以及其他 Pod 的网络栈相互隔离。如图 8-5 所示,Pod 通过虚拟以太网连接与宿主机相连,并且被分配了专属的 IP 地址。
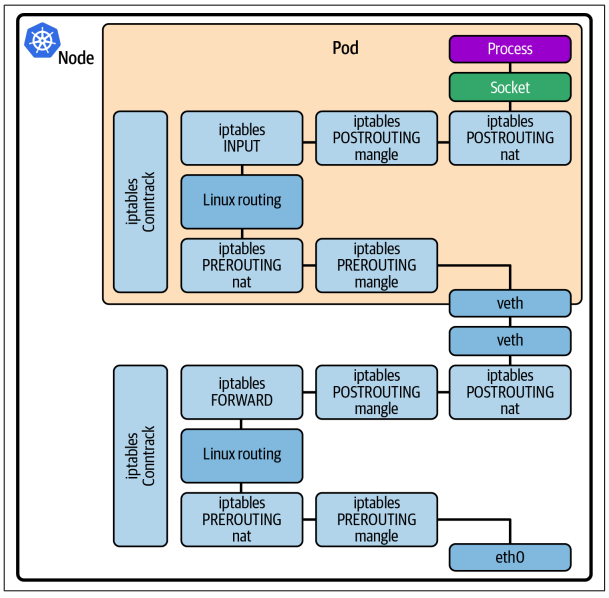
从图 8-5 可以看出,来自机器外部、发往某个应用 Pod 的数据包,需要先经过宿主机的网络栈,穿过虚拟以太网连接,进入 Pod 的网络命名空间,之后还要再次经过网络栈,才能最终到达应用程序。
这两套网络栈运行在同一个内核中,因此数据包实际上会重复执行两次相同的处理流程。网络数据包需要经过的代码逻辑越多,延迟就越高,所以如果能够缩短网络路径,通常就可以带来性能上的提升。
如图 8-6 所示,像 Cilium 这样基于 eBPF 的网络解决方案,可以挂载到网络栈中,覆写内核原生的网络行为。
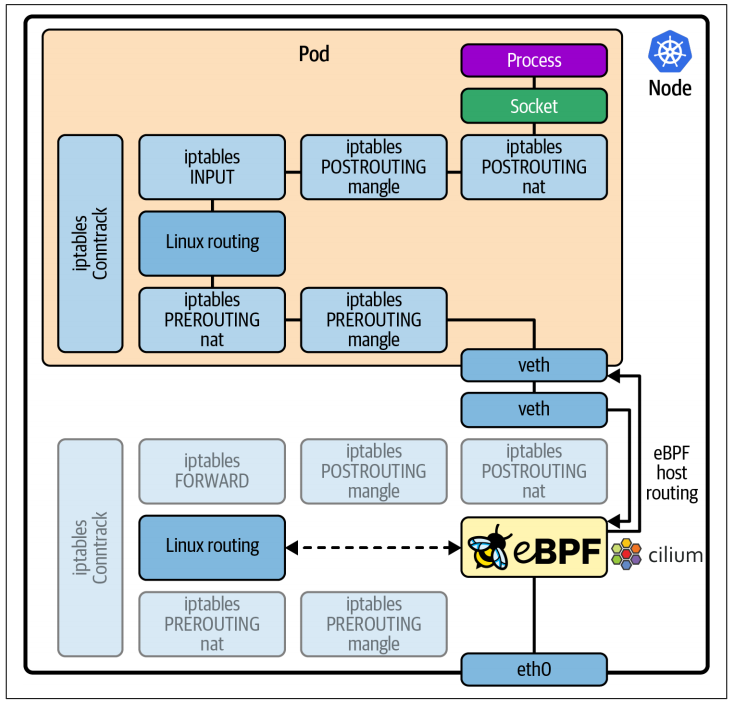
eBPF 可以用更高效的方案替代 iptables 和 conntrack,来实现网络规则管理和连接跟踪。
接下来我们就来探讨,为何这种方式能在 Kubernetes 环境中带来显著的性能提升。
8.6.1 Avoiding iptables
尽管 iptables 在传统的(容器出现之前的)网络环境中十分有效,但在 Kubernetes 环境下使用时,存在一些短板。在 Kubernetes 环境中,Pod 及其 IP 地址会动态地创建和销毁,每当新增或删除一个 Pod 时,所有的 iptables 规则都必须被完整重写,这在大规模场景下会严重影响性能。
Cilium 使用基于 eBPF 的哈希表映射来存储网络策略规则、连接跟踪信息和负载均衡查找表,这可以替代 kube-proxy 所依赖的 iptables。
相关阅读:
8.6.2 Coordinated Network Programs
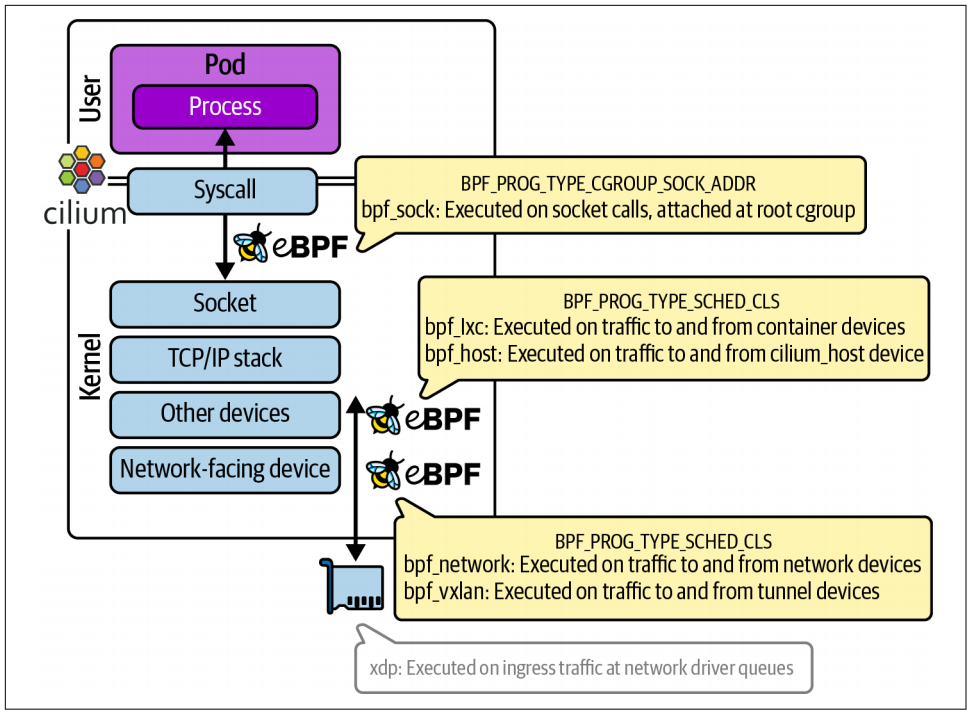
根据数据包的目的地是本地容器、本地宿主机、同一网络中的另一台主机,还是隧道,会有不同的 eBPF 程序被调用来处理流量。
8.6.3 Network Policy Enforcement
在传统环境中,IP 地址会长期分配给某一台特定服务器使用;但在 Kubernetes 中,IP 地址是动态增减、频繁更替的,今天分配给某个应用 Pod 的 IP 地址,明天很可能会被重新分配给一个完全不同的应用。这就是传统防火墙在云原生环境中效果不佳的原因。每次 IP 地址发生变动就手动重新定义防火墙规则,是不切实际的。
相反,Kubernetes 支持网络策略(NetworkPolicy)资源这一概念,该资源定义的防火墙规则,是基于为特定 Pod 所设置的标签,而非其 IP 地址。
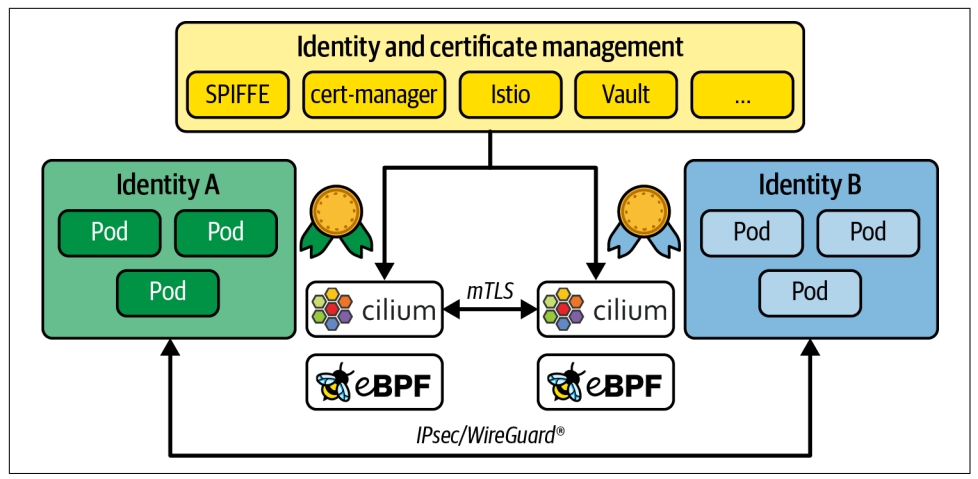
8.6.4 Encrypted Connections
在 Kubernetes 集群内保障流量加密的最简方案,是采用透明加密。它被称作 “透明”,是因为加密过程完全在网络层完成,且从运维角度来看极为轻量。
应用本身完全无需感知加密的存在,也不必建立 HTTPS 连接;该方案同样不需要在 Kubernetes 中额外运行任何基础设施组件。
目前有两种常用的内核级加密协议,分别是 IPsec 和 WireGuard ,Cilium 与 Calico 这两款 Kubernetes 容器网络接口(CNI)均支持在 Kubernetes 网络中使用这两种协议。它们会在两台机器之间建立一条安全隧道。容器网络接口(CNI)可以选择通过这条安全隧道,连接 Pod 对应的 eBPF 端点。
如今,eBPF 催生了一种全新方案,它在透明加密的基础上,采用 TLS 协议完成初始证书交换与端点身份认证,从而让身份标识能够代表单个应用,而非应用所在的节点,如图 8-8 所示。
8.7 Summary
在本章中,你了解到了挂载在网络协议栈各个不同位置的 eBPF 程序。我展示了基础的数据包处理示例,希望这些内容能让你初步明白,eBPF 是如何实现强大的网络功能的。你还看到了这些网络功能在实际中的应用案例,包括负载均衡、防火墙、安全防护以及 Kubernetes 网络。